Today over at ReadWriteWeb Sarah Perez wrote an article on how Google was gaining ground on their share of the search market. In the article she talked about the latest buzz from Google Analytics blog having to do with changes to the way Google.com handles clicks in their serps, which were a implemented as result of what Google would break in analytics packages by implementing AJAX driven search results. She notes that even though the speed benefit Google gains from going AJAX would be minimal on a per-search basis, when multiplied by the millions of searches performed every day it would eventually add up to more of a market share for them.
Although a change to AJAX technology would only make searches milliseconds faster, those milliseconds add up, allowing people to do more searches, faster. And that would let Google grow even more, eating up percentage points along the way. – Sarah Perez
However, what was missed by many in all of this is that when Google implemented this “fix” to retain the referrer, it wasn’t actually fixed in the way that they described in their blog post. What Brett Crosby highlighted in his post was the referring url itself that webmasters might start seeing in their traffic logs, and how it would be retaining the q= parameter for analytics packages to make use of, and nothing at all about how they were actually accomplishing this. He omitted these details even though he qualified the post in the opening by saying that they were writing it “for the most geeky among us”, and real geeks would want to know the nuts and bolts of what was happening. What neither he nor Google spokesperson Eitan Bencuya mentioned when discussing this is that the magic of retaining the referrer was not accomplished by simply coming up with a new url structure… due to the way that all major browsers function, just changing the url won’t fix the issue. Google engineers, to the best of my knowledge and generally speaking, are smart people. They know this. It simply cannot be done. Therefore what they did is to create a second, interim landing page that users are funneled though when they click on a link in the serps. This page then loads some Javascript that is processed, which when complete fires either a Javascript driven redirect or a meta refresh in the users browser, eventually bringing them to their final destination page.
If you happen to be getting served these new urls, you can see what the Javascript code on these new pages looks like by right clicking on the url and choosing to save the target. If you then view the file in a text editor, you will see code similar to this (there are a couple of variations on what code they are testing, apparently):
which was generated by saving this url:
http://www.google.com/url?sa=t&source=web&ct=res&cd=1&url=http%3A%2F%2Fwww.bad-neighborhood.com%2F&ei=YVbnSYraM5CNtgevkpzLBQ&rct=j&q=bad+neighborhood&usg=AFQjCNH7sp5nWWhaVsJafdeL1Rw8-TTXxA
Why does this matter? Well, remember, the gain that Google is getting from doing this switchover to AJAX is, on a per-search basis, minimal at best. It is in the area of milliseconds. Now to correct something that it breaks they are adding in two additional slowdowns to the navigation process… the delivery of more html, which although tiny does involve time itself to connect to the server and deliver the actual code, and the processing time of each browser to either interpret the Javascript or trigger the meta refresh. This not only nullifies any benefit that would be gained by switching to AJAX in the first place, in many, many cases it will actually cause the searches to be slower than if Google had just left things alone.
Google is aware of this too. Matt Cutts mentioned again the other day how he wished there was a better solution:

The problem is, of course, the better solution is to not make the changes. Unless all mainstream browsers recode the way that they handle url fragments after the hash mark (#), and Google waits until everybody in the world upgrades to those versions, it’s just not going to happen.
By the way, has anyone else noticed that Google is actually cloaking these new urls that they are delivering to people? If you happen to have your status bar turned on, and you mouse over a url in the serps, it shows you the final destination page instead of the actual one:
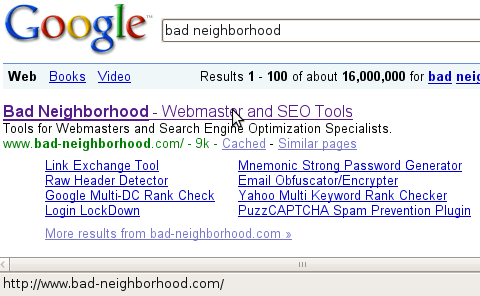
However, if you click on the url (even a right click), the true target suddenly appears:
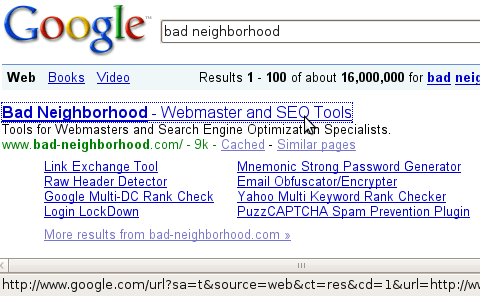
Not that big of a deal, I know, and nothing that they haven’t done before, but still. Between that and the “don’t bother reading this post, it’s just for geeks” intro on the Google Analytics blog post it almost seems like Google is making an effort to not have these new changes noticed. If this change is such a great idea, I would have to wonder why that would be.
Ha, whenever Google says something like, “Don’t bother reading this post, it just for geeks,” that means you should actually laser in on it.
I think the cloaking actually makes sense for the most users who expect to see the destination URL when they mouse over.
Anyway to stop the cloaked URLs from showing up in the SERPs? I hate having to open the page just to copy/paste the intended destination URL when firefox provides the oh-so-convenient “Copy Link Location.”
Thanks,
Guy
Hi,
i dont see the q=bad+neighborhood& in the string anywhere.
Do I need to go to google.com/url without being logged in?
Sound like a good ideal google has here i just don’t see where this benifit anyone but google but like everything
esle they have to work the bugs out