/sigh
Ok Jason, we get it, you’re desperate. But stealing content from Wikipedia in order to replace what you deleted? Come on!
I am flipping through Mahalo.com today, just seeing if you’re keeping your word or not, when all of a sudden I notice this huge amount of pages with odd names that somehow I missed before:
http://www.mahalo.com/cgs-20625
http://www.mahalo.com/cgs-9896
http://www.mahalo.com/cp-154-526
http://www.mahalo.com/daa-1097
http://www.mahalo.com/daa-1106
These are all nothing more than content stolen from Wikipedia. Your version:
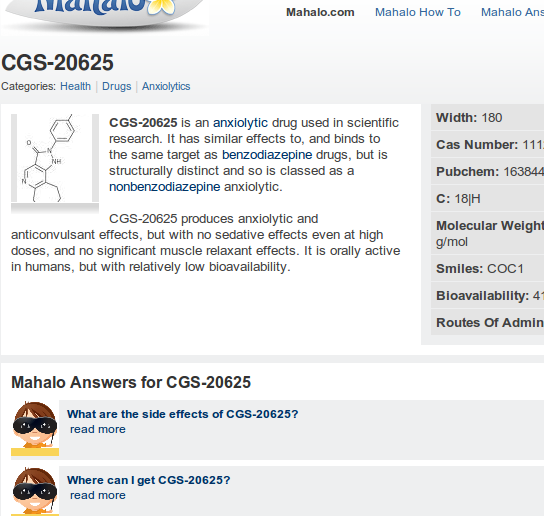

You even hyperlinked the same internal linking scheme to the same topics Wikipedia does, regardless of whether or not those pages exist on Mahalo.com. How the hell can you claim this is original content when it is nothing more than cut and paste? I mean, wtf, you just claimed that Wikipedia is nothing more than a free for all a little under 3 weeks ago… does the content somehow take on some magical value after you scrape it and host in on your servers, trying to pass it off as something one of your users wrote? THIS is the “our users build it” content that you were referring to?
News flash, Jason… your users and Wikipedia’s users are not the same people. You lumped Squidoo into the same category back then as well. If I look close enough, will I find content stolen from them too?
Now, to be fair, maybe this content existed all along but was much, much less noticeable when you had all of those other pages of fluff in there, but now that you have deleted 78% of that side of Mahalo, these scraped pages are practically impossible to miss. None of the pages I looked at were actually indexed in Google, but it looks like at least 27,900 of them currently are:
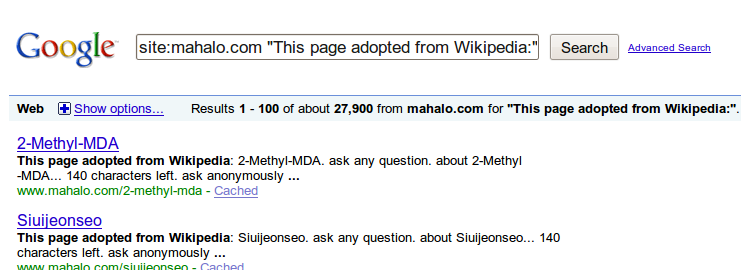
(Click to enlarge)
Considering that Google only has a portion of those indexed, and that at last count there were only 128,324 pages left on that side of your site, that means that at minimum over 21% (and in all likelihood 30% – 40%) of the remaining pages on Mahalo.com are these scraped ones. Is that really what you want on your “Human Powered Search Engine”…?
There are 2 major differences between the original content and your version. 1) The original content cites the sources directly there on the page, whereas Mahalo does not, and 2) Mahalo is using each and every one of these scraped pages to automatically create 2 (and sometimes 3) additional contentless pages under the guise of questions being asked anonymously, questions that no one ever actually asked, but that are there solely for the purpose of bolstering your indexed page count in Google. The first question asked of every drug is What are the side effects of {insert drug}?:
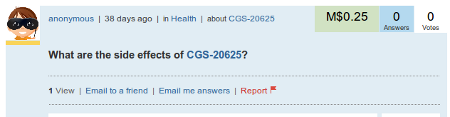
And the second is always Where can I get {insert drug}:
I also saw a “Who makes {insert drug}” question here and there as well. These are empty questions, asked by a bot, that for the most part will never get answered (or even looked at) and were never intended to. Three plus free pages (two of them completely devoid of content) for the price of one scraped page. Jason, seriously, do you really think you are slick doing this?
By the way, a huge number of those pages are less than 100 words in length, yet none of them have the noindex tag. Regardless of of what the length is, however, it’s not what you are claiming Mahalo.com is Jason, it’s more fluff. Wikipedia already gives us those articles. You add nothing to the interwebs by copying them. In all seriousness you should just go through and delete them all.
Wow.. JC was right! The free SEO advice is truly helping him to build an awesome web resource! All he has to do is delete these 30,000 pages as you suggested, after the other 100,000 or so he already deleted based on SEO advice, and keep going. Eventually (pretty soon at this rate) the Internet will be way better. WAY better.
Jason,
To be blunt if your respond to this by calling everyone terrorists, viscous, etc you are certainly loosing respect of this startup person..either get with the program or do not but don’t pull la Zuck and lie about it..
@John – Technically, it wasn’t 100,000 he deleted, it was 470,337. There are a couple of cool infographics on yesterday’s post to help put that into perspective. 🙂
@Fred who are you talking to, and what are you talking about? Who called who a “terrorist”?
@mvandemar
You’re good kid! I was wondering when someone would figure this out!
We are testing syndicating the Wikipedia to some pages BEFORE we build them out. There are about 3,000 of these and you’ve found them.
Add yes, we are seeding a couple of questions to see how that goes.
Also three more important things for you to cover:
{spammy link drops snipped}
i am really enjoying the show.
Michael, check JC’s twist podcast 2 weeks ago when he called SEO people terrorists..
Yea, he opened his TWIST show by saying that SEOs were “suicide bombers” and “terrorists,” which is interesting since Mahalo sells SEO services.
@Jason – “three more important things for you to cover”…? Wtf made you think this was the time or place to start spamming my comments with self promotional links? This isn’t a gd press release, Jason. This is an investigation into someone using slimy tactics on making money and Google letting them get away with it, despite am overwhelming amount of evidence and discussion, and an attempt to find out why they are. Quit acting so fucking glib about this… it’s not cute, not even a little.
How is it you expect people to believe that Google has 21k pages indexed, but there’s only about 3k of them? You think that Google has some sort of tardis indexing algo running, where your site is larger in their index than it is on their servers?
Whatever.
@Fred, my bad, I totally missed the fact that you addressed that to Jason in the beginning of your comment, it threw me off.
“@mvandemar
You’re good kid! I was wondering when someone would figure this out!”
Hahhaa. Yay! So, he gets an A plus on the final exam he didn’t even realize he was taking….
You see Michael, it was all a test, a test you didn’t even realize you were in the middle of…and you passed with flying colors.
Btw, is it Humphrey Bogart day at Mahalo. Why does he keep caling you “kid?”
Scribd.com is doing the same thing.
Jason,
You do not even pt the right license for the content you borrow.
Address the effing issue
Love your site! I’m so glad someone is exposing Mahalo for what it really is.
Jason Calacanis is now stealing content from Mahalo’s own writers! Jason is going to take all of the pages away from page managers and now those people get nothing for all their hard work. He has even changed Mahalo’s Terms of Service from “you own your content” to “All the content you write and submit to Mahalo . . . becomes the intellectual property of Mahalo.” How evil can one many be!?
So their TOS, dont allow to republish content, right?
But wikipedia should be free content with no copyright.