 For years now, on an on-again/off-again basis, Google has had issues with the way that they treat 302 Temporary Redirects. Going back at least as far as 2004, you can find discussions about websites getting hijacked in the serps, all due to problems arising from the way that 302’s were treated. The issue was that if one site redirected to another using a 302 Temporary Redirect (as opposed to a 301 Permanent Redirect, which has come to be known as a “search engine friendly” redirect), often times in the search results Google would display the URL of the source page, but the content of the page that was getting redirected to. This was open to being exploited, since malicious webmasters could simply serve a 302 redirect to Google, hence “hijacking” the target page in the serps, but then direct actual visitors wherever they wanted.
For years now, on an on-again/off-again basis, Google has had issues with the way that they treat 302 Temporary Redirects. Going back at least as far as 2004, you can find discussions about websites getting hijacked in the serps, all due to problems arising from the way that 302’s were treated. The issue was that if one site redirected to another using a 302 Temporary Redirect (as opposed to a 301 Permanent Redirect, which has come to be known as a “search engine friendly” redirect), often times in the search results Google would display the URL of the source page, but the content of the page that was getting redirected to. This was open to being exploited, since malicious webmasters could simply serve a 302 redirect to Google, hence “hijacking” the target page in the serps, but then direct actual visitors wherever they wanted.
Eventually, after much complaining from the webmastering community (and not until many webmasters had been adversely affected by it), Google changed the way that they handled 302 redirects. Supposedly, this fixed the problem. In January 2006, Matt Cutts discussed how those changes worked:
Many months ago, if you saw someresult.com/search2.php?url=mydomain.com, that would sometimes have content from mydomain. That could happen when the someresult.com url was a 302 redirect to mydomain.com and we decided to show a result from someresult.com. Since then, we’ve changed our heuristics to make showing the source url for 302 redirects much more rare. We are moving to a framework for handling redirects in which we will almost always show the destination url. Yahoo handles 302 redirects by usually showing the destination url, and we are in the middle of transitioning to a similar set of heuristics. Note that Yahoo reserves the right to have exceptions on redirect handling, and Google does too. Based on our analysis, we will show the source url for a 302 redirect less than half a percent of the time (basically, when we have strong reason to think the source url is correct). – Matt Cutts
Since that time, aside from the rare rumor here and there, 302 page hijacking pretty much seemed to be a thing of the past.
Last week, however, I noticed what appears to be a fundamental change in the way that Google is handling 302 redirects, and one that goes directly against what Matt blogged two and a half years ago. Until last week, one of the more commonly seen cases of 302 redirects in the serps, where the destination url is the one displayed, was the login screen for blogs powered by WordPress. When you try and access a screen that requires you to be logged in (for instance, /wp-admin/, or a private post), WordPress delivers a 302 redirect to the login screen, and includes a parameter in the url so it knows where to take you once you have actually logged in. Since Googlebot is never actually logged in to peoples WordPress installs, whenever it tried to spider a /wp-admin/ folder, you would see the page that was redirected to in the serps, like so:
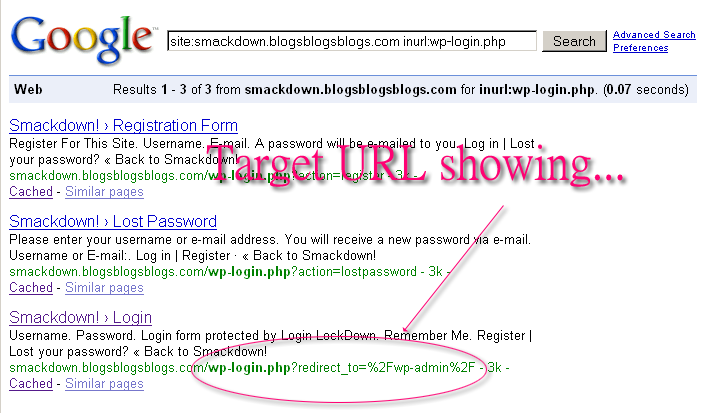
(click to enlarge)
Then, all of a sudden, it looks as if Google has started to change that, and is instead reverting back to showing the url that is actually getting redirected in the serps, but again showing the content of the target page in the cache:
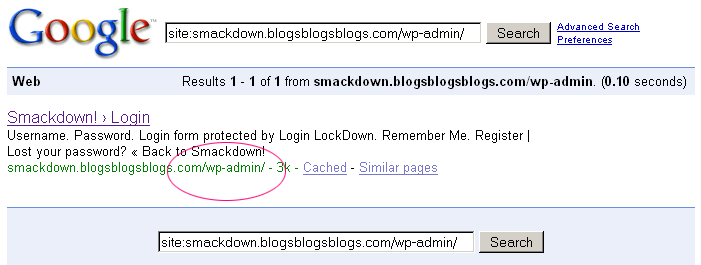
(click to enlarge)
This would of course lead me to believe that it is now possible to again hijack a competitors page by using a 302 redirect. With a little poking around, I was in fact able to find a case of this happening. If you perform this search, you can clearly see an instance of Google showing a source url that is performing a 302 redirect (I confirmed this using Bad Neighborhood’s Header Detector), and showing the content of the target website, and doing so across domains:
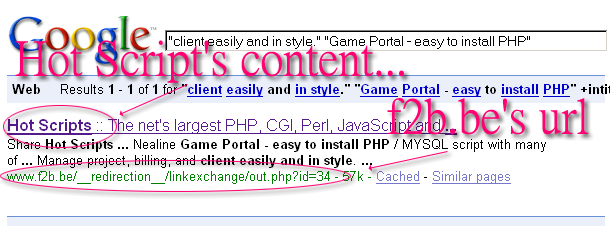
(click to enlarge)
Viewing the cached copy of the url in question (via [cache:www.f2b.be/__redirection__/linkexchange/out.php?id=34]) confirms that this is indeed a case of one site hijacking a page on a different site altogether. While this particular instance may be completely harmless, the fact is that the exploit itself is indeed back, and it is almost a guarantee that there will be webmasters that will get hurt by it. We can only hope that this time Google doesn’t wait quite so long to fix the issue, and that not too many webmasters are affected before they do.
Leaving a comment through Chrome.
Chrome test
John & Neyne, thanks for testing! 😀
Test test test, 123.
Too much pressure. 🙂 Give me 60 seconds. 🙂
LOL! Fine, upped it to 60 seconds. 😛
Help please, my site was 302 hijacked on this last 2008 september and it is been vanished from SERPS, it was due to a https layer pointing many shared ip web sites to my web site, i deleted this global https to return 404 pages but and now! should i ask for resconsidetation, should i ask to remove all redirect pages even with 404 status now? there is 254 pages from my web site as suplemental results of a PG 0 web site that is what i call really “LAME”, google should have choosen the source code page and not the poor redirect target page… I discovered this after researching a thousand posts, regards Claudio
Great read, i just had to do some redirects and needed some info on how google treated them, thanks for the info.