Last month Google revealed a new crawling method that they were testing out, whereby they were filling out forms on sites that they came across, in order to help facilitate the discovery of new pages. Matt Cutts discussed it here last month. I had noticed the phenomena as far back as last October, when I realized that a bunch of pages from Smackdown had gotten indexed that really shouldn’t have been. All of these new pages had a similar format:
https://smackdown.blogsblogsblogs.com/index.php?s=lube
https://smackdown.blogsblogsblogs.com/index.php?s=bestest
https://smackdown.blogsblogsblogs.com/index.php?s=scanned
Basically they were all search results that would return pages from my blog, since the phrases used were ones that were contained within posts, but none of them were things that anyone would actually be searching on. Since I was noticing that on occasion some of these searches were getting better indexed that the posts that they displayed, I decided to finagle my WordPress theme to exclude them, using the following code:
<?php
if(!is_archive() && !is_search()){
?>
<meta name=”ROBOTS” content=”ALL”/>
<?php
}else{
?>
<META NAME=”ROBOTS” CONTENT=”NOINDEX, FOLLOW”>
<?php
}
?>
This told WP that any search or archive (such as month or year) pages should contain the noindex and follow attributes, preventing them from pushing individual posts out of the serps while still allowing (in theory, anyways) any PageRank that they might have to be passed on. It worked, and soon thereafter those pages I had noticed were no longer indexed. I pushed the whole issue to the back of my mind, writing it off as a curiosity, no more.
Then, back in February, I noticed that someone was visiting those pages that had been deindexed, and that they were visiting them with the serps that they had been deindexed from as the referrer. I checked my traffic logs, and sure enough, the IP addresses of the visits showed that the visitors were hitting my site from within the Googleplex. This of course makes sense, since only Googlers would have the tools to be able to view pages that have the noindex tag in them as if they were in the serps anyways. My mind, as it typically does, immediately jumped to every type of conspiracy theory possible to explain why Google employees were investigating pages on my website (lil ole me) that I had chosen to keep them from indexing. Of course, then I saw that others were seeing the same thing (such as Gab from SEO ROI, who thought that Google Analytics was leaking), and shortly after that Google explained what was going on. Still, mostly due to the way that I discovered it, and the mistaken conclusions I had drawn at the time, my curiosity about this new feature had been sufficiently piqued. When I saw other examples of this behavior out there, it of course caught my eye.
About 3 weeks ago I suddenly noticed some new pages making it into the index that I’m quite sure were not intended to be there. According to what Matt Cutts had posted on his blog, the purpose of performing this new form crawl was strictly for the discovery of new links:
Danny asks a good question: if Google doesn’t like search results in our search results, why would Google fill in forms like this? Again, the dialog above gives the best clue: it’s less about crawling search results and more about discovering new links. A form can provide a way to discover different parts of a site to crawl. The team that worked on this did a really good job of finding new urls while still being polite to webservers. – Matt Cutts
Sounds good on paper. Problem is, it appears there are some unexpected side affects that go along with it. The sites I discovered these “new pages” on are both mortgage sites… one is Better Mortgage Rate, and the other GlenReiley.com, a site belonging to a Phoenix mortgage broker. The forms that Googlebot had discovered and crawled are not search forms, and in fact, insofar as standard HTML goes, are not really forms at all. They are instead interfaces for Javascript mortgage calculators.
According to the Official Google Webmaster Central Blog, the new method only retrieves forms that use GET as the method (as opposed to POST):
Needless to say, this experiment follows good Internet citizenry practices. Only a small number of particularly useful sites receive this treatment, and our crawl agent, the ever-friendly Googlebot, always adheres to robots.txt, nofollow, and noindex directives. That means that if a search form is forbidden in robots.txt, we won’t crawl any of the URLs that a form would generate. Similarly, we only retrieve GET forms and avoid forms that require any kind of user information. – Maile Ohye, GWC Blog
However, on both of these sites, the forms in question have no method declared at all. They have no action declared either, for that matter. The Better Mortgage Rate calculator form tag looks like this:
<form NAME=”temps”>
and the GlenReiley.com calculator form tag is even more basic:
<FORM>
According to W3.org, if there is no method in a form then it defaults to GET… however, in practice the majority of forms who do not have that explicitly declared, at least in modern (ie. post-1998) pages, are probably using the form for something other than server side scripting (which is the only type of form that would lead to new links being discovered). Additionally, W3C also states that there is no default for the action attribute, it is required for the form tag to be valid at all. The form crawling implementation of Googlebot ignores this, and instead assumes that without an action the page that the form resides on must be the intended target.
GWC Blog also states that if it does find useful pages through filling out these forms, it will include them in the index:
Having chosen the values for each input, we generate and then try to crawl URLs that correspond to a possible query a user may have made. If we ascertain that the web page resulting from our query is valid, interesting, and includes content not in our index, we may include it in our index much as we would include any other web page. – Maile Ohye, GWC Blog
Bold emphasis is mine. In the two cases I have listed, taking values from fields, mixing them up, and appending them to the url does absolutely nothing to the content of the page. In the GlenReiley.com site, when I discovered it, this meant that 6 identical copies of the same page were indexed with only the url differing in each case (cached version):
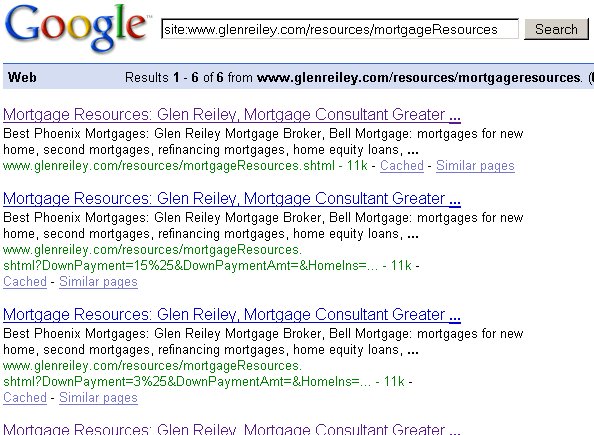
(click to enlarge)
In the case of Better Mortgage Rate, there appears to have been up to 172 of these fictitious pages indexed (cached version):
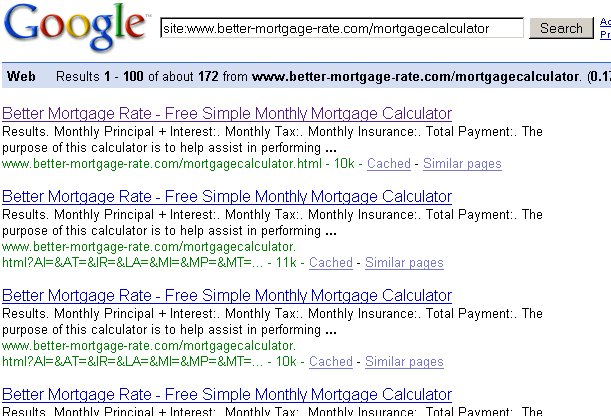
(click to enlarge)
Maybe it’s just me, but it does seem like a wee bit of a stretch to classify those as having content not already in the index.
Here’s the kicker. Again, according to GWC Blog, the pages “discovered” through this new crawl method can in no way adversely affect our current indexing:
The web pages we discover in our enhanced crawl do not come at the expense of regular web pages that are already part of the crawl, so this change doesn’t reduce PageRank for your other pages. As such it should only increase the exposure of your site in Google. This change also does not affect the crawling, ranking, or selection of other web pages in any significant way. – Maile Ohye, GWC Blog
I also asked Matt Cutts about it, and according to him as well, having these new pages shouldn’t be affecting anything (not negatively, anyways):
The main thing that I want to communicate is that crawling these forms doesn’t cause any PageRank hit for the other pages on a site. So it’s pretty much free crawling for the form pages that get crawled. – Matt Cutts
In the cached search above, you can see that there were 6 copies of the calculator page indexed for the GlenReiley.com site, including the original page. Now if you do a [site:www.glenreiley.com] (cached version), a total of 14 pages come up, only 3 of which are the calculator pages. The original calculator page, however, is missing. Additionally, the search by which I originally found the GlenReiley.com site, [“JavaScript enabled” “mortgage calculator”], had them ranking in the top 100. Now one of these new fangled “extra parameter” pages is instead showing for the query, hovering right around position 193:
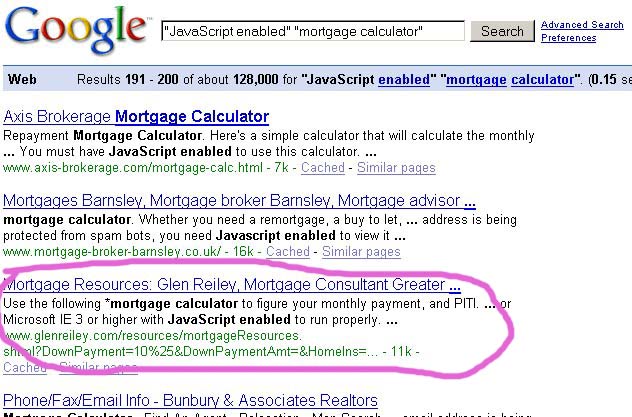
(click to enlarge)
To me it seems that for this to be unrelated to the form that was crawled would be one hell of a coincidence.
If Google is going to make this new form crawling a part of their mainstream discovery, then perhaps they should consider implementing some new element to the Robots Exclusion Protocol, maybe something along the lines of a NOFORM meta tag. At the very least, they should stop filling in missing attributes (ie. method or action), and only crawl forms that explicitly lend themselves to it. If they don’t tighten it up, and the clutter (and possible detrimental side effects) I found only worsen, then honestly, I don’t see there being a point of them continuing it at all.
Mike, I’m not sure if the terms matter and if we’re thinking the same, but in case we’re not, I thought the new crawling was aimed at discovering deep web content – like orphaned pages – on quality domains. Not at discovering links.
The difference (as I see it) is that if the purpose is to discover new links, then it can matter for links pointing outwards to other sites too. My understanding of the point of the crawling was the 80-20 rule being applied to search – 80% of the high quality stuff coming from 20% of the sites… Ergo if a site is high quality, let’s try and index ALL of it (but not necessarily who/what it links to). (More detail if you click my name; it goes to a page where I guessed what the rationale behind discovering these new pages might be.)
I mean, with circle-of-trust type algos, I guess discovering external links comes to the same thing as discovering more pages on the site you’re crawling. Depends how cynical you are about high quality sites linking out to their sponsors etc though…
All that said, your search tech knowledge is greater than mine, so I’d love to get your take!
p.s. The flip side of the canonical issues is at least those guys know they have trusted sites now!
Gab, I was just quoting what Matt Cutts had said, but yes, I would take it to mean essentially the same thing as you did. “New links” would be links leading to new content, not new links pointing to content that they already knew existed.
Recently we discovered we were being overload by queries from Googlebot. I guess it’s something to do with this issue you posted about, because our phpBB2 forum’s tables are overloaded with a lot of nonsense searches. Strangely no one of this searches seems to be indexed at Google as you can see here: http://www.google.com/search?q=site:www.fillos.org+inurl:search
Anyway, we’ll try to forbid index.php?name=PNphpBB2&file=search for any bot at ROBOTS.TXT. It should help, don’t you think?
Thanks for telling people about this issue. Overload of dynamic content site is a main collateral issue of this new Google’s behaviour.
As a second line of defense we might try to add a captcha to that forum form 😉
this is slightly off topic, but google now discovers search functions on sites and lets you use them from the search bar. Try browsing around in chrome and then typing in the domain name while on the site. If the site has a search feature Google has identified it will give you the option to search with that feature. Its like the open search without creating the xml file required. Kinda nifty.