That’s right… today Matt Cutts completely reversed his opinion on pages indexed in Google that are nothing more than copies of auto-generated snippets.
Back in March of 2007, Matt discussed search results within search results, and Google’s dislike for them:
In general, we’ve seen that users usually don’t want to see search results (or copies of websites via proxies) in their search results. Proxied copies of websites and search results that don’t add much value already fall under our quality guidelines (e.g. “Don’t create multiple pages, subdomains, or domains with substantially duplicate content.” and “Avoid “doorway” pages created just for search engines, or other “cookie cutter” approaches…”), so Google does take action to reduce the impact of those pages in our index.
But just to close the loop on the original question on that thread and clarify that Google reserves the right to reduce the impact of search results and proxied copies of web sites on users, Vanessa also had someone add a line to the quality guidelines page. The new webmaster guideline that you’ll see on that page says “Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.” – Matt Cutts
Now, while the Google Webmaster Guidelines still specifically instruct webmasters to block these pages, Matt himself appears to have changed his mind on the issue. Today on Twitter, Matt said this:

The link that Matt provided was to a story discussing the differences between the robots.txt file for the whitehouse.gov website under the Bush regime (cached copy), versus the brand spanking new one that went up as soon as Obama took office. Matt apparently likes it because it means that as far as Google goes, there is “much more crawling allowed” with the new file:
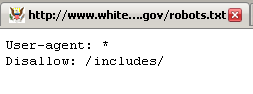
He’s right, of course. The new version only restricts one directory (for now, anyways), the /includes/ one, whereas the old version contained 2,305 path restrictions that pertained to Google (and every other bot, for that matter). Let’s take a look, however, at exactly what the old version was blocking from being indexed:

The first line is for /cgi-bin, which it is quite normal to block. The next 11 lines blocked are all search type pages. Now, even though the Google Webmaster Guidelines very clearly state that those pages should be blocked, since Matt is saying that “more crawling allowed == Matt likes” I would strongly suggest that people not block them in their own robots.txt*. For real. Cause as we all know, Matt > Google Webmaster Guidelines. Seriously.
Some of you may be wondering about the other 2,293 restrictions in the old file. If you look at the restrictions starting at the 13th path listed, and on through the rest of them that Google is supposed to obey, every path ends with /text. Those were the printer friendly versions of other pages, and indexing them would result in duplicate content getting indexed in Google. Last year in February, Matt had this to say about blocking duplicate content:
I often get questions from whitehat sites who are worried that they might receive duplicate content penalties because they have the same article in different formats ( e.g. a paginated version and a printer-ready version). While it’s helpful to try to pick one of those articles and exclude the other version from indexing, typically.. – Matt Cutts
That, however, was last year. As Matt clearly indicates in his tweet today, regardless of what the content actually is, how it was generated, or how many copies of it exist, he would much prefer less restrictive robots.txt files in the future.
Thanks for clarifying, Matt. 😀
UPDATE: Ok, I just got alerted to the fact that these new and improved Whitehouse.gov “allowed pages” are already making it into the serps:
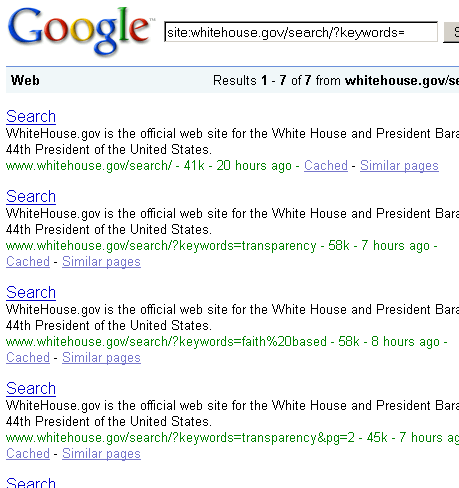
Thank you John Honeck for the heads up.
I dont understand why people are so fascinated by Obama’s robots.txt file. They put a brand new web site up, so they obviously need to dump the old robots.txt, and more likely than anything they haven’t had time to update or figure out what directories they need blocked.
@JOE my thoughts exactly, give him 8 years in the White House and it may be just as long 🙂
BTW great post and being a programmer I loved your use of the logic operators as descriptors!
Joe, you’re being entirely too reasonable. 😉
Looks like they’ve added Disallow: /search/ now.
Aye, they did that a couple of days ago. Did they give you any credit for pointing out what happens if they didn’t, or me for making everyone aware of it? Nooo… of course they didn’t, the little ingrates. 😛
Hmmm… I think the Obama team are naieve… after a few months of journalists crawling through the onsite search pages indexed by Google they might wise up.
Maybe its now the case that Google will no longer penalise for duplicate copy from the same domain. Since only 1 pages is generally featured on any given serp it doesn’t matter to Google which one is displayed. Maybe the second will appear as a supplimental?
Perhaps this was not the case when Matt made his original comment.