A couple of days ago I posted my assertion that Rand Fishkin had lied about the details of the new Linkscape tool on SEOmoz. During the discussion that followed, Rand continued to maintain that they owned the bots that collected the data that powered the tool, despite several points on that being very unclear, and that his bots had collected those 30 billion pages.
Right in the heat of the argument, someone decided to drop a comment on my blog that struck me as a little odd for some reason:
So who’s behind dotnetdotcom.org? “few Seattle based guys” “Trust us” ? WTF!? Why are there absolutely no names on that site? – some guy called smallfish
I had looked at that site before when Rand had released all of the info as to where the data from his tool actually came from. I had dismissed it, since Rand was claiming to have 30 billion pages in his index. The download on this site was only for 3.2 million pages out the initial 11 million pages that they had collected so far, what they were calling “the first part” of their index.
Since right at that moment Rand and I were arguing about whether or not Linkscape actually had a bot of it’s own that had collected the pages in their index, it hit me. “Aha!”, I thought. “Rand is probably going to reveal at some point that they actually own the DotBot. I mean, being able to say that you collected 11 million of the pages is better than having not collected any of them, right?”
So, I trotted off to dotnetdotcom.org to take a second look, just in case that turned out to be what was happening. Once I got there, I notice that something was different. When I had visited the page on Friday, these were the stats I saw:

(Click to enlarge.)
Saturday night, however, when I went to look, this is what I saw:

(Click to enlarge.)
That’s right… smack in the middle of an argument between Rand and myself, where he was insisting that he owned a bot capable of spidering an index of the size he was boasting, one of the sources he listed (the one that no one knew who the owners really were) jumped 7 billion pages in size. Talk about your random coincidences.
Let’s take a peek behind the scenes here, and see exactly how they managed to accomplish this truly humongous task. Viewing the source on the page, we can see that the counter is driven by a Javascript routine:

(Click to enlarge.)
What it does is it starts with the date that the DotBot went online, which is June 10th, 2008, calculates the number of seconds between then and now, and uses that as the starting point for how many pages it has spidered so far. It then counts up the display at one page per second.
While obviously this would only be an estimate of how many pages were crawled, this is a perfectly reasonable way to do it. For a smaller, non-Google sized company, with a server dedicated to nothing but crawling web pages, grabbing a page a second is about what we would expect. However, what they did next is another story altogether. How did a company capable of spidering a page a second around the clock get such an amazing boost in capacity? When we view the current Javascript, we see this:
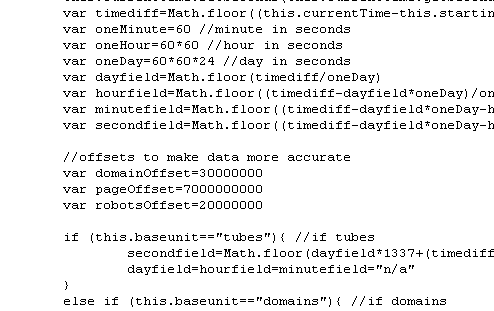
(Click to enlarge.)
All they did was add in 7 billion pages to the start number, and added in a proportional boost to the other factors they are displaying as well (domains, robots.txt, and “clogged tubes”). They even left the clock counting up at 1 page per second. 😀
Now, to put that in perspective… 7 billion pages at 1 page per second would in fact take 7 billion seconds to spider. This is not counting any processing or indexing time, this is just the collection of the raw data itself. That is:
116.6 million minutes
or
1.94 million hours
or
81,018 days
or
221 years (not counting leap years or time travel, of course)
in order for them to actually gather all of those pages. And they’re claiming that they did it in 4 months.
Uh huh. Right. 😀
I figured even if my hunch about this being related to the Linkscape issue was wrong, it’s still noteworthy that a company that is self professed to be worried about making the internet “as open as possible” would be trying to pull a fast one like this.
That’s a ludicrously cheeky move! Congrats on digging this up, it takes a certain kind of inquistive bastard to find things like this. I’m glad you stumbled on it.
But of course if you scooped up 7 billion pages from “other sources…”
I especially like how in the first and second screenies you can see that they multiply the dayfield by leet (1337).
The shite keeps getting deeper and deeper. It’s so deep now for seomoz; there are no boots created/made/invented high enough to keep that shite from flooding.
What you’ve demonstrated here is dotbot’s clear and brazen effort to lie and deceive the viewing audience. Surely this has nothing to do with SEOmoz.
Sean, that depends. I wrote this before people started posting the evidence that moz does in fact own DotBot. You’re right, if they don’t own it then it’s probably not related… though even if I was wrong about the two being connected it was still worth discussing.
It just seemed way too damn convenient that the prime suspect for being SEOmoz’s primary source of data suddenly jumped in capacity from being able to spider millions of pages since they were created to billions of pages, right in the middle of Rand and I debating his assertion that moz did in fact spider 30 billion pages all by themselves.
I know I’m a little late to all this, and I haven’t read it all carefully but:
The whois for dotnetdotcom.org says it’s registered to a Jeff Albertson aka – http://en.wikipedia.org/wiki/Comic_Book_Guy
And regular readers of SEOmoz know that only Rebecca would know enough Simpsons trivia to be that clever (except perhaps myself).