Yesterday a friend of mine, Sebastian, wrote a post titled, “How do Majestic and LinkScape get their raw data?“. Basically it is a renewed rant about SEOmoz and their deceptions surrounding the Linkscape product that they launched back in October 2008, a little over 15 months ago. The controversy is based around the fact that moz basically lied about how it was exactly they were obtaining their data, which in part was probably motivated by wanting to make themselves look like they were more technically capable than they actually are.
Now, I covered this back when the launch actually happened, in this Linkscape post, resulting in quite a few comments, and there was more than a little heated conversation in the Sphinn thread as well. This prompted some people, both on Sebastian’s post and in the Sphinn thread on it, to ask why all of the renewed interest?
It is not extreme, its just that it isn’t new. The fact that they bought the index (partially)? That was known from the beginning. The fact that they don’t provide a satisfying way of blocking their bots (or the fact that they didn’t want to reveal their bots user agent)? Check. The fact that they make hyped statements to push Linkscape? Check. {…} I don’t get the renewed excitement. – Branko, aka SEO Scientist
Well, I guess you could say that it’s my fault. Or, you could blame it on SEOmoz themselves, or their employees, depending on how you look at it. You see, the story goes like this…
Back when SEOmoz first launched Linkscape, it would have been damn near impossible for a shop their size to have performed the feats they were claiming, all on their own. Rand was making the claim “Yes – We spidered all 30 billion pages”. He also claimed to have done it within “several weeks”. Now, even if we stretch “several” to mean something that it normally would not, say, 6 (since a 6 week update period is now what they are claiming for the tool), we’re still talking a huge amount of resources to accomplish that task. A conservative estimate of the average website, considering only html, is 25KB of text:
30,000,000,000 websites x (25 x 1024) bytes per website = 768,000,000,000,000 bytes of data (768 trillion bytes, which is 698.4TB)
(698.4TB / 45 days of crawling) x 30 days in a month = 465.6TB bandwidth per month
Now, I know that one of the reasons that Rand can get away with some of his claims is that most people just don’t grasp the sheer size of those numbers. In todays age, bandwidth is cheap, with many hosts even boasting of unmetered, or unlimited, bandwidth on their accounts, and computers are fast. But in reality the reason they can make those claims is that in all likelihood no one on a shared server or a cluster will ever hit their bandwidth limit, because their processor usage will cause them to go over their limits way before actual data transfer becomes an issue. On dedicated servers, where the resources are not shared, hosts actually care about how much bandwidth you use. For instance, last August The Planet (one of the best hosts I know of for dedicated servers) upgraded their plans to offer 10TB/month at no additional cost. Prior to that they only included 1TB with their plans. On most hosts the charges for people who go over their bandwidth allotment are usually rather steep.
This means that basically for what Rand was claiming to be 100% true, they pretty much would have needed to own their own datacenter. Now, these days, of course, there is another option. Five months ago a new company, named 80legs, came out of beta. With 80legs pretty much anyone can build their own spiders, run them on 80leg’s servers, and spider 2 billion pages per day. They can do this of course because they rent the service out to many people, it’s not just one company powering one link tool. However, 15 months ago when moz launched their tool, 80legs wasn’t an option.
So, I called them on their claims, and a bit of controversy followed from it. Moz refused to clearly identify how they were actually gathering the data, and would not release information on how to keep whatever spiders were being used off of their sites. They did release a list of fairly widespread bots, and suggested that if you wanted to keep SEOmoz from scraping your sites via robots.txt, well, then, you’re just going to have to block Google, Yahoo, and MSN as well. They also came up with their lame assed version of a “solution” to people’s concerns, and stated that people could also add an SEOmoz meta tag to their pages to keep them from being indexed (which would not, however, keep them from being crawled in the first place). Despite the fact that many webmasters made it clear that this was unacceptable, to date nothing about that situation has changed. They still do not offer a clear concise way to allow webmasters to instruct SEOmoz to not spider their site, or give people an option to keep information about their site from showing in the Linkscape data.
The thread on Sphinn went where it did, and the next day one of the admin’s decided to close the discussion, even though it was far from being resolved. No more comments were allowed. Period. End of story.
I moved on.
Fast forward 15 months. I get an email from SEOmoz, touting their new tool, which is apparently powered from the Linkscape index. So, I trot on over and take a look. There, on the front page, are their same outrageous claims… only more so. The graphic stats that in the past 45 days, they have crawled 700 Billion Links, 55 Billion URLs, and 63 Million Root Domains:

Now, I and others, when this first happened, put Rand to task for trying to interchange “crawling” with “indexing”. Therefore, when he states in that graphic that they “crawled” 700 billion links in 45 days it’s not because he’s too stupid to know the difference. The SEOmoz employees know very well that they while they may have “found” an huge amount of links in their index, they did not crawl them. This is actually aside from whether or not it was them who did the actual crawling. Of course, they do try and set toss in some confusion there, just in case someone calls them on their bullshit again, by stating that they crawled 55 billion urls at the same time, as if there is some sort of relevant distinction between a url and a link… which, for crawling purposes, there isn’t. The only real way there would be a difference is if they were trying to say that 645 billion of the links they found were mailto: or javascript: links, but even if that were the case, you wouldn’t “crawl” those anyways.
So, upon seeing this I of course get irked all over again. I went back and revisited the unresolved Sphinn thread that had gotten locked, just to refresh my memory of how the conversation went. I got to the end of the conversation, and I saw something that struck me as just a teensy bit odd:
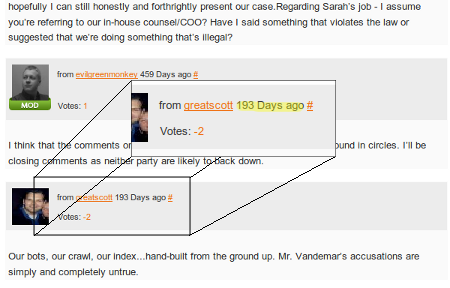
Wtf? Apparently Scott Willoughby (note: please see update below), an employee of SEOmoz, contacted an admin or mod on Sphinn a little over 5 months ago, 9 months after the conversation ended, and had them unlock the thread, all so he could post this way out of left field comment calling me a liar, and then had them lock it again. I mean, seriously. Why the hell would someone do that? A little over 5 months ago… hm… what happened 5 months ago… wait! Wasn’t that when 80legs.com went live? I wonder…
So, off I went to look at the list of “sources” that SEOmoz had listed on Linkscape. Lo and behold, there it was:
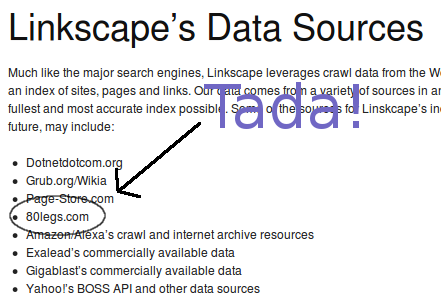
So it seems that what happened is that in the summer of 2009 SEOmoz learned that there was a new service about to go live, one that had it existed way back when Linkscape launched would have provided an alibi to moz’s claims, one that would at least put them in the realm of feasibility. Therefore they went through the effort of having the thread re-opened, just so that someone could post one more claim that yes, they actually did crawl their own data. Of course, this still doesn’t explain a damn thing about what user agent they were (or are, for that matter) using, or how to keep those bots from hitting your site. Apparently someone in the organization felt strongly enough that it is possible to have future technology retroactively bolster bullshit claims that they actually went down the path of trying to cover their tracks that way.
I sent some messages to Sebastian about all this, since I knew he’d get a kick out of them yet again trying to confuse people about spidering vs. crawling, and that prompted him to blog about the whole thing again.
On a side note, I do want to address a recurring theme that keeps coming up in the comments throughout this whole issue. Some people are asking, if the tool is useful, who cares if they lie to promote it? Without getting into the whole argument over whether or not link intelligence is worth $800/year when the majority of it is available for free, there are both ethical as well as legal ramifications about what SEOmoz is doing. One of the biggest selling points for this is that this data is presented with SEOmoz’s own metric, something that they have dubbed as mozRank (mR). This metric is exclusive to SEOmoz, and only holds value if it’s not more made up bullshit. If they do indeed get exposed for selling snake oil, then anything sold under the pretext of “we’re experts… trust us!’ becomes worthless.
Additionally, they are still gathering this data without full disclosure on how to keep their alleged bots off of our servers, and therefore doing so without our permission. According to the Revised Code of Washington 9A.52.110 (SEOmoz is headquartered in WA), Computer trespass in the first degree:
(1) A person is guilty of computer trespass in the first degree if the person, without authorization, intentionally gains access to a computer system or electronic database of another; and
(a) The access is made with the intent to commit another crime; or
(b) The violation involves a computer or database maintained by a government agency.
(2) Computer trespass in the first degree is a class C felony.
So, it’s only a crime to deliberately scrape people’s content if your are doing so in conjunction with committing a crime. According to RCW 9.04.050 False, misleading, deceptive advertising:
It shall be unlawful for any person to publish, disseminate or display, or cause directly or indirectly, to be published, disseminated or displayed in any manner or by any means, including solicitation or dissemination by mail, telephone, electronic communication, or door-to-door contacts, any false, deceptive or misleading advertising, with knowledge of the facts which render the advertising false, deceptive or misleading, for any business, trade or commercial purpose or for the purpose of inducing, or which is likely to induce, directly or indirectly, the public to purchase, consume, lease, dispose of, utilize or sell any property or service, or to enter into any obligation or transaction relating thereto: PROVIDED, That nothing in this section shall apply to any radio or television broadcasting station which broadcasts, or to any publisher, printer or distributor of any newspaper, magazine, billboard or other advertising medium who publishes, prints or distributes, such advertising in good faith without knowledge of its false, deceptive or misleading character.
While many of us may take it in stride that we will get lied to when people try and sell us things, trust me, it still does not make it acceptable, and there is law that backs that up.
Update: Apparently there was a glitch in Sphinn when they migrated to new software. The comment that I accused Scott Willoughby of making 9 months after the conversation had been closed (which would have required the involvement of a Sphinn employee) was in fact a Desphinn that he made at the time the post was first submitted. This glitched caused that and 1,530 other Desphinns to all incorrectly get imported as comments… and all with the exact same timestamp, ie. 7/14/2009. Whoops. 🙂
Thank you to Michelle Robbins, Third Door Media’s Director of Technology, for discovering how that actually happened. It does prove that not all conspiracy theories are true. 😀 I do, however, stand by the rest of the post.
Now I’m assuming everyone who’s been tearing SEOmoz a new asshole over the last couple days has nothing against them personally, only in regards to certain things pertaining to LinkScape, would that be correct?
That being said, I’ve really enjoyed all info that has been put out and the debates between everyone.
Good post Michael.
@Domenick – I can’t speak for anyone else on this, but my only beef with Rand has all been surrounding similar stuff throughout the past few years, each time having to do with his honestly levels, or pretending to know stuff he doesn’t in order to make himself look better. As far as that goes, however, there does seem to be a recurring theme of me calling him on his shit. You can find a few posts in that vein on this blog (ie. Rand Fishkin and the Troll Defense), as well as threads on the various seo forums here and there.
You know, this “you must be envying SEOMOZ” every time someone criticizes SEOMOZ thingy is getting old. When people start doubting my motivation behind the criticism, I know I am spot on, since they would have argued with the arguments if they could.
About the post: W-O-W
1. Awesome investigative blogging. I do not understand what idiot still thinks they can pull one like that on you.
2. Holy crap. Why is it so hard to be straightforward? Why? Majestic is doing it and i have never heard one complaint about them. Just learn from your fucking comptetitors, for goodness sake.
Michael
Thanks for helping to clarify how this got re-awakened, and for that perfectly awesome part where you busted SEOMoz for injecting the alibi into the already closed Sphinn article.
I began writing my own article on the topic of SEO industry people being sheep to slaughter last night, but now I don’t know if it’s worth the bother given your excellent article.
Personally, I don’t care if anyone labels any of us as being jealous of Rand or moz in general because that’s people who are either unwilling or unable to see the reality you’ve so eloquently described. And more likely, it’s just coming from people who have put them on the pedestal, just like Tiger Woods fans.
Bottom line here is I don’t trust SEOMoz tools or any other similar tools from any company. Heck I only give enough value to Google’s tools to just be a baseline reference and nothing more.
If people aren’t willing to put in the true footwork that it takes to get quality results without such tools, then I say good for them – suckers, every one. Sheep to slaughter. Making others wealthy on hyped nonsense.
And as far as the refusal of the SEOMoz team to allow blocking of their data, that either confirms they don’t have their own data, which would invalidate their claims, or that they’re just another corporate sham willing to disrespect the very community they profit from.
Mike: Gotta admit you were correct way back when I was disagreeing with you. Even for those of us that don’t grasp 20% of the technical arguments (okay for me not 10%….that sneaky deal w/ reopening the sphinn thread and how you connected them w/ 80legs, its history and its current usage by moz….. It paints a very incredible sneaky story connected with Moz’s actions.
Meanwhile the whole deal ends up making moz nice money, getting moz some followers who swear up and down with/ and by them, and giving credibility to a group wherein the credibility seems dramatically undeserved.
Man, you should get an investigative reporting award for this story.
Meanwhile it looks to me like sphinn, SEL, and Moz have some explaining to do.
Hi Michael
80legs is powered by Plura, a grid computing system, which uses idle PCs to do the crawling (Similar to the seti @home project).
The useragent is 008 so I believe if you want to prevent 80legs and their users/clients from crawling your site you can add this to your robots.txt
user-agent: 008
Disallow: /
Reuben, thanks, good info. 🙂
No idea if that helps block moz tho. If they’ve been lying since the beginning about where the data comes from, then there’s no way of knowing whether or not any of the sources listed are real or just anti-information chaff they tossed out there to keep people from knowing what’s what. Still, good to know about 80legs. It would be nice, since they supposedly allow people to design their own crawls, if pages fetched under the direction of a particular client also identified that client via the useragent, and allowed blocking of them specifically.
I signed up for a free account on 80legs and tried it out. I created a “job” and went through the settings. There wasn’t an option to specify user-agent, so I’m assuming that it’s hard coded into the client, so blocking that UA will block all requests from 80legs.
Of course that’s not retroactive, so it won’t remove pages that have already been crawled by 008.
And unlike Google webmaster tools, you can’t request URLs to be removed, because the results from their crawl are provided to the user in the form of a CSV which will be downloaded and processed separately.
Michael,
I’m the CEO of 80legs. This article came across my desk, and it’s certainly raised a few eyebrows over here. Please contact me directly with any additional details you think might be useful.
Thanks,
Shion
Shion – I sent you an email. If you didn’t get it please check your junk mail.
Thanks.