 Ok, so, looks like Rand and gang finally decided to reveal their top-secret recipe about how they gathered all that information on everybody’s websites without anyone noticing what they were doing. There was quite a bit of hoopla over the fact that when they announced their new index of 30 billion web pages (and the new tool powered by that index), due to the fact that they never gave webmasters the chance to block them from gathering this data. In fact, they never even announced their presence at all.
Ok, so, looks like Rand and gang finally decided to reveal their top-secret recipe about how they gathered all that information on everybody’s websites without anyone noticing what they were doing. There was quite a bit of hoopla over the fact that when they announced their new index of 30 billion web pages (and the new tool powered by that index), due to the fact that they never gave webmasters the chance to block them from gathering this data. In fact, they never even announced their presence at all.
While this is a huge breach of netiquette as it pertains to crawlers, at least today Rand finally announced that they are now disclosing their sources for data. In fact, this was how he worded it to the community:
we are now disclosing our sources for data – Rand Fiskin, SEOmoz CEO and really, really open guy
Better late than never, right?
The thing is, as I was looking over the list of bots that you would need to block in order to prevent mozzers from gathering your data, I noticed this subtle, easy to miss pattern in what they were listing. You have to look really, really close to see it, and the untrained eye might never see it at all, but luckily, eventually, I did see it for myself:
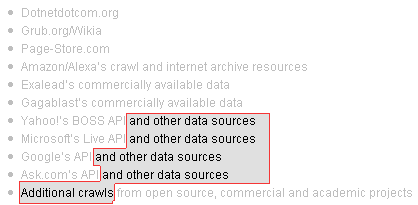
That’s right folks, if you do decide to keep moz out by blocking all of the big guys (Google, Yahoo, MSN, Ask, Amazon, and Alexa), the lesser known guys (Dotnetdotcom, Grub, Page-Store, and Exalead), and that one fictional guy they threw in there (Gagablast), you still won’t have them blocked. Fear not though… after much work, I finally figured out that Rand was indeed true to his word, and that they did in fact release enough information to block the bots. All you have to do is add the following lines to your robots.txt, and you’ll be golden*:
User-Agent: *and other data sources
Disallow: /
User-Agent: Additional crawls*
Disallow: /
See? I got ya covered! 😀
Seriously though, despite the fact that Rand and Co. are still less than forthcoming about all of the bots that are used (I’m guessing he doesn’t actually know, to be honest), something much more revealing is highlighted in this information, namely, they lied about having their own crawler.
Let’s take a quick review of some statements Rand made in the initial announcement about the tool:
- Our crawl biases towards having pages and data…
- As others who’ve invested energy into crawling the web…
- our crawl biases towards this “center”…
- Our process for crawling the web…
- Moving forward, we’ll… invest in better and faster crawling…
- In comparing our crawls against the engines…
- we’ll be releasing more information about our crawl…
You also have statements made by moz employee Nick Gerner like this:
- we’re crawling everything we can…
You even have him claiming bullshit like this:
We do prioritize the crawl according to pages we think are important. For now, and probably for the foreseeable future we’re going to rely on link endorsement to make that decision. Make good content, get good links. Keep it publicly available. We’ll get there soon enough – Nick Gerner, moz employee
That’s right, not only did they claim that they were crawling the web, they wanted us to believe that they prioritized how they crawled based on an importance algorithm! 😀
I have to admit, Rand, it’s pretty bold to basically admit this late in the game that you guys lied through your teeth and grossly misrepresented the facts, just so you could appear to have accomplished a much bigger task than you actually did, all in the name of getting more money from webmasters. That’s a much bigger admission than saying you cloaked your bot, if you ask me. Gratz on coming clean.
I think the time has come to block all bots by default and to only allow choice bots to craw your site.
user-agent: *
disallow: /
user-agent: goodbot1
disallow:
user-agent: goodbot2
disallow:
Jay, actually I don’t mind the crawling part. Unless a bot is actually putting a strain on my server, or from a scraper, it doesn’t bug me. The thing that got me with this whole deal is that I knew from the beginning that they didn’t suck down those pages themselves, and were just trying to look like they could do more than they actually can. It was feigned added value.
I mean, think about it… even if they had a server farm that was sucking down 50 pages a second, 24/7, it would take them 600,000,000 seconds to hit the 30 billion pages that they are boasting. That’s 6,944 days, or 19 years to get the initial index built. They are claiming to have done it in 1 year, and that they will have enough new data every month to make for meaningful updates. There is no way they were gathering that data themselves.
They support meta noindex but notice they don’t mention support for meta nofollow
Sorry about that – obviously, it was supposed to be Gigablast (lousy typos). Gagablast sounds like some sort of infant vomit 🙂
And Andy – we treat meta nofollow the same way the engines do – they don’t appear in our link graph or any of the calculations. I’ll ask the guys to add that to the information page.
Now that is a response that is to the point. This changes the whole perception now that we know Rand meant Gigablast and not Gagablast. Phew. Already feeling better.
hahaha!
Mad weather.
I will certainly be blocking all bots. Let’s build another internet, outside of Google and the CIA
So who’s behind dotnetdotcom.org? “few Seattle based guys” “Trust us” ? WTF!? Why are there absolutely no names on that site?
@smallfish – they’re no one special, I’m sure. There are tons of small companies and organizations out there that grab pages to analyze the data. The index they make available for download only accounts for .01% of the index that moz is boasting, from what I can tell.
Interesting to note that their claim of having spidered 7,011,296,117 pages since June 10th of this year would have required them to be able to spider approx 614 pages per second, and their counter is only advancing at 1 page per second.
Of course, even more interesting to note that apparently exactly 7 billion of those pages were supposedly spidered some time in the past 3 days. 😛 Something’s not right with them.
Very troubling. You make excellent points Michael and in a very clear way. Something never seemed right to me from the very moment this new link thing was launched. Then, when Rand “finally” announced his sources about 1 1/2 weeks later, it all became extremely clear.
Very troubling. I don’t believe something like this can be rectified. Character and judgment are separates many in this industry from others. It was oh so very clear at the start that moz wanted the industry to think that had an actual “crawler”. This is a huge difference between a “crawl” and a “crawler”. The mozzer backers can spin this all they wish, but the actual facts are hard to ignore.
And yes; Michael is very correct; there is absolutely no way to block the linkscape stuff from your own site. Doing so just might be having you also block stuff you might not want blocked from the major search engines who actually give you something in return for the actual crawling of your websites.
BTW – I tried to address many more of Michael’s concerns and explain more about the crawl and yes, crawlers that built the data in Linkscape’s index on the Sphinn thread – http://sphinn.com/story/79700.
@doug – that’s not accurate. If you read our sources pages, you can see exactly how to block Linkscape from listing your sites/pages without blocking any of the engines. We obey the robots meta noindex tag, but also an seomoz noindex if you just want to target our index.
I did read it Rand. I read it when you first announced the data last week. It wasn’t clear to me at all. Is it now? If so, and we all noindex with a meta tag, how do we know it was followed? Considering the smoke screen perpetrated at the launch, we are simply suppose to trust things as they are? Further; how about “other sources” you are not disclosing? What if I want those sources crawling pages but not having to do with linkscape? Pages you already have in your tool from out there are going to be in there for how long? If the site puts up this meta tag noindex thing, how long will those pages be in… the ones in before you even launched?
There is an implied industry specific code of conduct in regards to bots and tools and anything else having to do with our websites. Do you think you fulfilled this code of conduct with your tool?
Further; why didn’t you simply tell all of us at launch exactly what was what?
Further still;
http://www.seomoz.org/ugc/official-linkscape-feedback-thread
At the very start of that thread, “your” guy named Nick Gerner who has LOTS to do with the development of your tool also made it certainly seem like you had your own bot “crawling” the web. Please read all his comments and just try to come to some other conclusion. I defy anyone to know at launch that you in fact didn’t have your own crawler/spider.
So now; let’s say we all do have a definitive way to block your stuff; That way is to stick in a site wide noindex tag just for you. In other words, opt out of your stuff. What do we get for all that trouble? We do this anyway for bad bots and for pages we don’t want indexed in the major search engines, etc, so what do we get from you for all of this? We either subscribe to your tool and have a tic for tac as competitors have our data so we can have their data, or we do nothing at all and get nothing at all for doing nothing. In fact; we get the priviledge of knowing competitors may have our data, including you. Tell me the exact benefits we get for simply doing nothing?
Please note I am not speaking for my site at all as I don’t give a flying “F” about what others may know, but I am speaking for all other site owners who don’t know much and don’t know about this and never will. What benefit is it to them? Do they get free referrals from you or something, like you do with google? Site owners who know nothing even get referrals from the se’s for doing nothing but allow their pages to be crawled.
Oh, and this from Danny Sullivan;
“I was surprised that blocking information wasn’t up at the time the tool was released. Even stealthy Cuil/Cuill put up blocking information *before* they released their product.
Bottom line, if you’re going to crawl the web and to be a good web citizen, then you obey robots.txt blocking. If you don’t, then you’re not a good citizen in my books.
Rand says blocking will be added, so great if that happens in short order. I know what it’s like coming off of a trip. What’s not clear is how quickly the existing data will be dropped. If they don’t recrawl that often, then site owners then site owners who don’t want to be in the database have to wait for a revisit, then wait for removal.
Possibly they could add an instant remove tool, but that’s a lot of work (you have to verify who owns a site, etc.)”
That was nine days ago, just after you launched. It’s VERY clear he was under the impression you had your very own crawler/bot considering what he wrote about things at the very start. You know he doesn’t consider me a friend, but he certainly does you. If even he was duped by all of this, it’s not a stretch why or how well all were.
Rand, when you so frequently admit making fairly significant mistakes, at what point do you expect to lose the goodwill of the community and no be trusted?
As I said earlier, I would highly suggest you analyze the way your company works. I understand you’re busy but with the millions you got from the VC would it be that hard to have someone dedicated to putting out fires like this?
The fact that it took you a week to release user agent info is just pathetic. The fact that it took you more than a day to remove an offensive post that was published on your blog is unacceptable. I realize you and the mozzers travel but hire a PR person for crying out loud!
You’re accurate in the assessment that we didn’t reveal sources when we launched, and now we have. You can choose to block them, or just have us exclude your pages from showing in our lists of data. If you want to confirm, just use the tool – it will take until we re-crawl those pages that have the seomoz meta tag for us to exclude them (and we update once per month, so hopefully 30-60 days).
And since we DO have spiders that fetch the data, and those spider names are now public, I don’t see the disconnect. I think this is playing at semantics and interpretation – our bots aren’t called “linkscape” or “seomoz” but we do have bots gathering data for our index – there’s no other way to build an index.
I agree that when we launched, we should have disclosed the UA sources at that time – we thought during development it would be unwise, but have come around. I apologize for that delay.
Ok, now I’m confused again as to what you are claiming.
Just to be clear, are you claiming that you have bots, but they are disguised as Googlebot, msn, etc? Or are you claiming that you own the bots belonging to those search engines? Or did you mean something altogether different when you listed those as your “sources” for data?
Also, wasn’t one of the biggest sales pitches for Linkscape the fact that other people’s data was inaccurate? And yet you’ve now revealed that you rely completely on that unreliable data of other bots?
I think the issue here, Rand, is that you promoted so heavily your ability to crawl the web and gather your own data but now are saying that the value lies in your ability to compile others’ data into useful reports.
Those are two drastically different things.
Wow; I’m with Michael.
Rand; your last post makes no sense. I was clear before about how and why you lied at launch, but now I’m not clear about anything you are doing.
I suggest you shut the heck up now.
The source names are all listed – those we use now and those we may use in the future. The product was promoted as a link graph of 30 billion pages that we collected, and that’s exactly what it is. The collection process was done through spidering the WWW with the UAs and sources you see listed on our page.
It feels like I keep saying the same thing over and over again. Am I not explaining it clearly? Maybe I’ll try one more time:
#1 – Linkscape is a) an index of the WWW that currently contains 30 billion URLs. The crawl to retrieve this data was designed by SEOmoz, based on the metrics we created like mozRank and using the idea that we had a preference for domain diversity (reaching as many domains as possible) over reaching deeply into subpages and subsections on individual sites. This index is consistently updated – approximately once per month, with the first estimated update around Halloween. Future updates will focus on keeping the data fresh (i.e. re-crawling stuff we’ve already seen) and expanding into new territory that we haven’t seen (but have seen links to).
#2 – Linkscape is also a tool that lets you see this link graph data for any page or site in our index. This includes links with lots of features (nofollow, image links, links that are hidden, etc.) and sorting (by any of the metrics or by searching for particular keywords in the title, url, or anchor text) and metrics (like mozRank and mozTrust).
#3 – Linkscape’s data sources are listed on this page – http://www.seomoz.org/linkscape/help/sources – if you’d like to block individual bots, you can do that and if you’d prefer that specific pages didn’t appear in our list of links you can use the seomoz or robots meta noindex tag.
Doug – there’s a big difference between lying at launch (which would be to claim that which is false) and not revealing, which is what we did. Now we’re doing neither – we make the claim, which is true, that Linkscape has crawlers, which we disclose, and we make the claim that we designed, built and continue to refresh the index, which is also true. The “lie” of omission is a fair one, but these others are not – anyone using the tool can easily see and test that it’s factual.
Ok, so, again, just for clarity, when you say this:
You are indeed talking about blocking Googlebot, Yahoo! Slurp, etc… you utilize data that is contained in your index that was initially collected by those bots, correct?
I mean, let’s be very, very clear here. You do not list a single user agent on that page you linked to. What you list is a variety of sources that you obtained the data through, and each of those sources has user agents associated with them. Those bots can be detected via their respective user agents, and those bots can be blocked via robots.txt, since those bots all adhere to the Robots Exclusion Protocol. Would you say that all of that was accurate so far?
There simply isn’t a clear way to block the linkscape stuff. I said as much a few days ago in the feedback thread. Moz won’t give us a clear way either as doing so would not be in the best interest of his investors. This is a money kind of thing for sure. The hell with morals or any kind of code of conduct because mozville is a SEO.
BTW: Michael; I see that “spin” place already shut down comments on your blog post. After one day, and over the weekend, and way before the start of the work week, sphinn.com shuts down comments. Ironic? No surprise to me.
MVD: I have a suggestion for you. Since comments are cut off at sphinn, many just might want to comment in here instead, but the fact your captcha is quite the pain, I suggest you change it. Sometimes it takes me ten or more tries to get it right. I’ve left in the past from you when trying to comment. I’m very sure it’s chasing away many posts.
@Doug, to be honest I don’t think most people have an an issue with it. If it helps, it’s always a single 5-6 letter word (not just letters), no spaces, no junk in the middle. If it’s not obviously a word, flip the left and right sides.
@Rand – still waiting for that clarification.
Sorry – took a few hours off. The comment you made sounds nearly right to me, though I wouldn’t concentrate on just the two sources you mentioned. The list you’ve got in the post is currently comprehensive and we’ll update it anytime we use data from a new source. We specifically say that we may now or in the future use those sources, and that’s as detailed as we’re getting publicly for now.
Doug – you are correct regarding investors and finances. This tool is not a noble effort to bring peace and freedom to the land. It’s made by a for-profit company, and the only way it will be successful is if the value it provides to members is consistently high. We designed it as a commercial product and the initial launch decisions not to reveal sources and the current messaging are intended to help protect the company’s interests and competitive abilities.
BTW – The comments are kind of challenging with this captcha, but so far, I’ve been able to figure it out OK. I suspect non-native English speakers might have a more challenging time, though.
Rand,
Just to reiterate
I quote your comment -“And since we DO have spiders that fetch the data”.- If you do have spiders, why not let the block be through a server robots.txt block rather than bloating the server. Can you imagine the code bloat if 30 other seo companies follow you with their own tools. None of your explanations above made sense to me. Your comments remind of me of the circling settler wagons fighting the Indians, trying to gain time till the imaginary cavalry comes. Mike, after your dynamic url blog on Google and now going after this issue I nominate you to the blog of the year.
Mert – we are letting folks block through robots.txt. We list all the data sources and all have bots/UAs that can be blocked if you so choose. How did none of my explanations make sense? I don’t know how to be more clear about it… Maybe I need a whiteboard or something.
@Skittzo – somehow missed your comment in the shuffle, so I’ll try to address that, too.
Yes – a big part of the selling point is that other data is both misleading (as Yahoo’s inlink counts also include nofollows) and incomplete – no one else shows 301s/302s/meta refreshes. We also felt that data like Google’s PageRank wasn’t accurate in some cases (where they’ve penalized in the toolbar) and certainly wasn’t specific enough. In a logarithmic scale, which toolbar PR uses, a 5 might be anywhere from five to ten times more important than a 4, and not knowing whether your site is a 4.1 or a 4.9 is pretty frustrating – mozRank attempts to address that by showing precision to two decimal places.
Other inaccuracies we’re trying to address include the time between PR updates – 3 to 9 months, with no visibility on when the next update might be. We update every month and the data pushes out at that time.
There’s also no visibility into anchor text or image links or many of the other flags that we assign to links in our graph from any of the other tools and Linkscape’s data is meant to be accurate in that way as well.
I did not mean to suggest that Google or Yahoo! had an inaccurate crawl of the web – I don’t think anyone came away with that impression. I meant that link data is frequently poor, old, inaccurate and not detailed enough and Linkscape addresses those issues through all the points I mentioned above and many more.
Mike, did my earlier comment get held up in moderation?
Rand, for starters, telling people that if they want to block your tool via robots.txt then all they have to do block every major search engine plus a few lesser known ones is:
a) ludicrous, and
b) a lie.
Even if it was a reasonable suggestion (and let’s again be very clear, it is not), you put right at the bottom of the list, “Additional crawls from open source, commercial, and academic projects.” So, according to what you listed, unless someone were to block everything via robots.txt, one or more of your “additional” sources might still gather the data, and it still wind up in your index.
Additionally, this brings us back to where you claimed dominion and control over the spiders that collected the information. You stated that you had an algorithm that determined which sites and pages they spidered next. You based these claims on the basis that Linkscape had its own crawler, and that simply is not true.
@Gab – I don’t see any other comments from you. You’re on the approved list, they would go straight through.
I’m not getting this at all Rand. If people in this thread alone are not getting it, what makes you think the industry gets it either? In my opinion the only people who might get it are the people who just don’t care….IE: mozzers in your little circle. They don’t care what you do or how you do it, so they don’t want to understand the process either. You could screw them very directly and they wouldn’t know it. LOL
Many others do care about a firm who attends most every search conference, and speaks at all of them, and promotes themselves to the ninth degree, and is buddies with the leader.. Danny Sullivan. We care about how that firm is doing business. In YOUR own words: “are intended to help protect the company’s interests and competitive abilities.”
So do WE want to protect our competitive abilities as well. What works for you also works for the entire industry. I don’t like the FACT that unless I PAY/SUBSCRIBE to YOUR tool, I don’t have the data that my client’s competitor does. I don’t like the FACT that I cannot block your shite using robots.txt unless I also block google and yahoo and MSN as well. Come on now. LOL
I don’t like the FACT that I get a little meta tag from you to stick on all my pages, and MAYBE they won’t be in your index… just maybe. The thing is; the page might not be included, but what about the links? Blocking VIA robots.txt if Farrrrrr different than blocking using a meta tag.
I also think it’s funny stuff that mozzers everywhere think they are getting some great data all about links. We all know however that your tool does not tell you what Google actually thinks about that link. Not sure how relevant your data could be. Michael Martinez had a great post about this exact thing. I agree with him totally.
That being said; the way you launched this tool was very deceitful. You seem to find a way to piss me off in the end, and after I had grown to actually think your firm just might be “best practices” after all.
There is such a thing as an implied code of conduct within the SEO industry. There is such a thing as reasonable expectations of good business practices among like minded firm’s, and firm’s who want to do good for the industry. In my opinion, you have failed at this on all counts. I’m greatly disappointed with most everything involved. You might not think little o’l dougie’s opinion means a damn thing….. probably not, but we shall see.
@DougHeil Linkscape to me is a huge boon in the competitive intelligence landscape as well as a way for me to objectively evaluate my own website content over time and in comparison to my competitors. What @randfish and team have accomplished is putting together a lot of disparate and fractured content into one convenient place and applied an (arguably) objective evaluation of it.
Competitive intelligence is a factor in every business sector and the Internet and, more specifically, SEO is certainly no exception.
So what if @seomoz didn’t provide this date. You can get similar data from other places, but now I don’t have to pay as much for it, which for me is a huge advantage. Yes, my competitors can also learn about me, but they could in the past too so it’s really not that much of a change.
I know this comment is probably going to get flamed for “sticking up for the mozzers” but I’m really trying to be fair and objective. I know and understand (at least I think so) why you don’t like it, but as I said, this data is already out there. The only way to hide it is to take your website offline or go members-only and not allow any indexing which is impractical.
@randfish and team have taken data that normally would be out of the price range of small to medium SEOs and placed it within our control, which I for one, am glad to have.
@Marty – I just want to make it clear that nothing I am talking about in this post has to do with what I think that the the tool’s actual value is. I only used the free version, and I personally wasn’t that impressed, but that’s not what this post is about. I build tools that do rely on freely obtainable data, but that put all of that data in one place, and automate querying it, and there is value in that. Even if I think that moz is way overpriced, I am not saying that is worthless, and honestly, that’s not the issue at hand.
The issue is the selling tactics of presenting the tool as if it were built by a company capable of doing much, much more than what they actually are. Anyone can build a gocart in their garage. If someone builds gocarts, and sells them saying they were built using Porche motors, or tell you that they’ve been building gocarts for thirty years, then it better damn well be true. If you bought one under those premises, and then down the road you discover that they used Honda motors and only started building them 6 months ago, you’d probably be pissed, regardless of how well it ran.
Rand billed his tool as being something that he and his company built by having spidered 30 billion pages themselves. This was a lie, plain and simple.
Marty; Fair point by you. That being said; considering that I know SEO as well and sell MY services in regards to that, why the heck would I use another SEO’s opinion about what value some link has? That’s nutty. You seem to be a SEO as well, so I have to wonder why you value judgment from another SEO over your own tools and data and judgment?
Anyway; I agree with the above as I really don’t care about his tool or the value or lack of value at all. That’s not my concern as I would NEVER personally use some silly tool out there to tell me what is what. Don’t have to. No need to. I do care about why and how a firm in our industry goes about their business under the guise of “best practices”. What the moz firm has done and how they went about the launch and what they have said about the tool from the very beginning, is about as far away from “best practices” as I know of. Period.
That’s the issue. That’s the point.
Also, Rand, it’s blatantly obvious that even the industry leaders assumed that you guys had done all of the spidering yourselves. For example, when Rustybrick wrote this:
If your intent truly was not to deceive, then why did you make no attempt to correct this misconception? In fact, you did quite the opposite. According to Rustybrick:
That is something that you could only do if you did in fact control all of the data sources from the crawling end of things. You had to have known that. This isn’t even close to “semantics”.
So – I think the reason you’re upset is because we didn’t release a single UA, but instead a list. In that list might be sources we built and designed to crawl the web and others we use to bolster our data if/when those sources can’t reach data that we know we need to build a comprehensive index.
It was not a lie to say that we built a spidering process or an algorithm to determine crawl rate or designed the crawl itself and the de-duping parameters, the way link juice flows, or any of the other claims. None of them were untrue. The problem I see here is that we’re being intentionally deceptive in order to protect the quality of the product and discourage competitors from being able to copy what we do.
However, I stand by the fact that a lie of intentional omission is not the same as a direct untruth. Your accusations are lies in that they are not true. My claims are true, but don’t reveal everything.
On the last point regarding Barry’s post on SERoundtable – I think that was a miscommunication. I said that we’d be revealing ways to block us and ways to avoid inclusion in our results, but Barry took that to mean a single UA. I do apologize for that – we chatted only briefly in person and at that time, I hadn’t even met with the team to figure out a protocol, and knew only that we were going to be providing a way to be excluded from the public index.
Um, no. And again, you have to know that’s not what I am saying, and this has to be deliberate obfuscation. That’s actually kinda rude, Rand.
Let’s try for a couple of simple direct, yes or no, don’t require expounding on, questions. These are not trick questions, and I would ask that you please at least start your answers to them in a yes/no format:
1) Did your company spider the 30 billion pages used in the Linkscape index?
2) If the answer to #1 is No, then would you say that your company spidered most of those pages?
And before you try and redefine the term, spidering a page means going out and fetching it from the server that it is hosted on.
1) Well, our engineers built the crawler, built the spidering method, designed the crawl and our funds paid for the crawl, hosting and processing bandwidth/storage, so the answer is yes. The bots that crawl did not come from SEOmoz’s servers nor did they use a UA other than what’s listed on the sources page.
The reason this is confusing is because we’re being intentional about not revealing the whole story. I know that’s frustrating, but it’s the truth, and so are all of our claims. Like I said – for competitive and quality reasons, we’re not telling the whole story here.
@rand I have a technical question. Let’s say I want to block the Linkscape from accessing my site’s information. And let’s say I am so upset about this whole thing that I am willing to block all the bots from your list, including the major SE bots, in addition to adding the meta that you provided. How does it work from now ? I have to wait until all of your data providers provide you with a dump that includes the updated version of my site ? Which they will not have since I blocked them. So you will have all of my site’s data up to the point when i blocked the bots ? Or do I need to first add the Linkscape excluding meta tag, wait for your data providers to cache that version of the site so your script can “understand” that it is being blocked and then I block the robots from your list ?
I’m sorry, but you are now claiming that your engineers built Googlebot, Yahoo! Slurp, etc., since those are all listed as your sources? You didn’t simply buy the data available from Exalead and Gigablast, you designed the crawl engines that power them?
The crawl is the process of getting the pages from the servers, not “filter the data we buy from you by x, y, and z criteria”, just so you know.
SEOmoz says that the meta tag with name=seomoz can prevent Linkscape from using a particular webpage in their data. That means that SEOmoz does have a bot that retrieves webpages. The fact that they have nofollow link data also means they must download the actual contents of webpages. Or am I missing something?
So why can’t we get the UA for SEOmoz’s bot that downloads webpages? I don’t want to add a meta tag to every single one of my webpages just to block Linkscape. I would be so much simpler just to add it to robots.txt.
Tummblr, if they purchase the data from someone else then that would not require them to do their own spidering. As long as non-standard meta tags are included in the data that they purchase, then they could just filter it out by querying that data.
The actual contents of 30 billion webpages are available for sale or collectable from search engine APIs? Wow. I was thinking they buy/collect 30 billion URLs, but download the contents of those webpages themselves.
Well, see, that’s just it. Rand is now claiming that despite the fact that they list 10 known and an uncounted additional unknown sources for the data, they did indeed design the spidering engine and crawled all 30 billion pages themselves (see comments #35 and #36 above). He has yet to explain what he means by that, but that is his claim.
Michael – I’m most definitely not claiming we built Google or Yahoo! – that’s ludicrous. My “claim” is exactly what I stated above, and that includes the crawl fetching portion. Are there additional direct questions you want me to answer related to that?
Neyne – If you block all the bots, it means that we won’t be able to grab future data from you. Our index updates once monthly, so, like Google, we’d have to re-crawl, see the block and then exclude you from the next index update. With the meta tag, the same is true – you’d need to have it up when we come and visit, so that it would be pushed to our index and wouldn’t show in results. I realize that means a delay, but this is the same way it works with search engines. If you block Google, they won’t remove you until they recrawl and rebuild their index.
Tummblr – the 30 billion pages we’ve collected are not for sale by any engine or provider I’m aware of. You can buy some crawl data from some of those providers and we may, now or in the future, use those purchasable sources to bolster our data.
Just a guess, but perhaps Rand means that they have a spider that crawls all those databases he listed where he gets his data from? (If that’s the case though, I’m not sure why he doesn’t just say so, so that’s probably not it.)
No, Rand, again, you cannot redefine terms at your convenience. I clearly stated this in my question:
With that caveat you answer that yes, you guys spidered 30 billion pages, just like you initially claimed to have done. Since you list as your sources for where you got your index all of the major API’s and 2 places where you can purchase the data, either your engineers built those bots that did the work (which would be what you claim when you both claim those as your sources and say that “our engineers built the crawler, built the spidering method, designed the crawl and our funds paid for the crawl, hosting and processing bandwidth/storage”), or those things you listed are not actually your sources.
Those cannot both be true. This isn’t a word game, Rand. Downloading data that someone else compiled, data that would have been spidered even if you did not exist, is not the same as you spidering that data yourself.
Which is it? Did you spider all 30 billion pages, or not? We’re not talking about whether or not you spidered any of the data… did you or did you not spider all of it?
Yes – We spidered all 30 billion pages. The sources and UAs are listed on the sources URL.
No – We did not build bots for the major search engines.
I’m so confused. Simple yes or no question:
Does SEOmoz directly download any content from my website?
If you’re asking, does a bot named SEOmoz come grab data, the answer is no. If you’re asking whether bots come and grab data that goes into Linkscape, the answer is yes and the list is at the sources URL – http://www.seomoz.org/linkscape/help/sources
Ok, Rand, look at what you are saying. In the “Yes” portion above:
“We” = “The sources listed”
“The sources listed” = Google, Yahoo, Exalead, Gigablast, etc., therefore
“We” = Google, Yahoo, Exalead, Gigablast, etc.
And Tummblr, the question really is, did SEOmoz directly download all of the content from everyones site in their index. That’s what he is saying.
That’s not what I’m saying or what I’ve said. I’m saying three things:
1)Linkscape has an index
2)That index was built by crawlers we control and may, now or in the future, pull data from any of the sources listed.
3)We didn’t build bots for any of the major search engines.
I think my above answer to tummblr holds true for your modified version of the question as well. Sources listed on that page did download all the pages in our index for use in Linkscape.