Earlier this week at SMX Advanced Seattle, during the You&A With Matt Cutts, the topic of the latest Google update, dubbed Mayday by webmaster last month, happened to come up. According to Ryan Jones’ live blogging account of the SMX Keynote the update had nothing to do with the web spam team. It was an algorithmic change that was intended to “make long tail results more useful”. Matt made statements in effect telling webmasters who might have been affected by MayDay that they should look at their content and see how usefulness or unique content could be added to those pages. This indicates that the point of the Mayday update was to filter out or penalize results that are not unique content, or that are simply autogenerated results.
Matt made similar statements when he was interviewed by WebProNews and the topic came up:
How do I make sure that I am returning the highest quality content, stuff that’s really useful for users, whether it’s editorial discretion, unique content user generated content, you know, stuff that’s not available anywhere else, versus just something that’s scraped, or duplicate, or really kind of lower quality. – Matt Cutts, explaining how not to get penalized by the Mayday Update
During the keynote, in response to Matt’s explanation of what Mayday was supposed to accomplish Danny Sullivan indicated that he hopes that this update will help filter out results from content mills like Mahalo. Mahalo certainly sounds exactly like what Matt was describing, as I have written about in the past.
So, did the Mayday update actually accomplish filtering out this “low quality” content from the search results? I went back and checked some of Jason Calacanis’ spam pages on Mahalo that I had blogged about in the past. Unsurprisingly enough, most of the pages I checked were still ranking just fine in Google. What was slightly unexpected, however, was what the listing looked like for one of them, [need for speed walkthrough]:
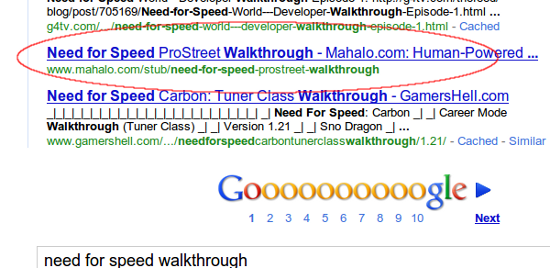
Notice the lack of a snippet for that listing in the search results? That is because due to my earlier write-ups about Mahalo and Google, in an attempt to keep up appearances with Matt Cutts, Jason had the team move a bunch of the pages that I wrote about into a directory named /stub, and then blocked that directory via robots.txt. When Google encounters blocked content that has enough link juice it lists those pages, like you see here, as url-only. What Google usually doesn’t do, however, is actually rank those pages well in the search results.
Thinking that maybe it was a fluke, and that perhaps that particular listing just had some extra ranking power because I had blogged about it before and therefore it gained a few extra links, I delved further. This is just a sampling of what I found:
[fallen angel walkthrough] (#4)
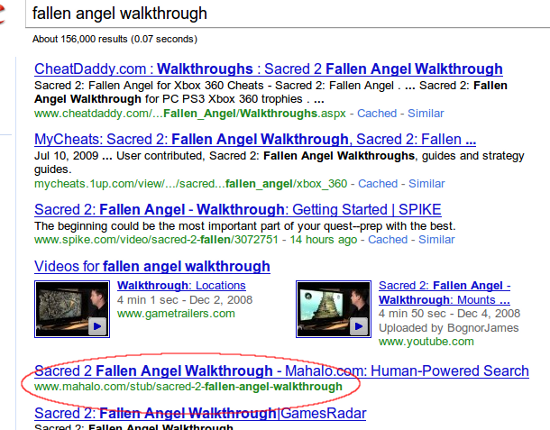
[jack keane walkthrough] (#7)
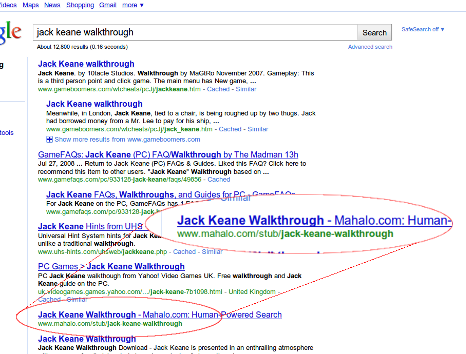
[how to plan thanksgiving dinner] (#7)
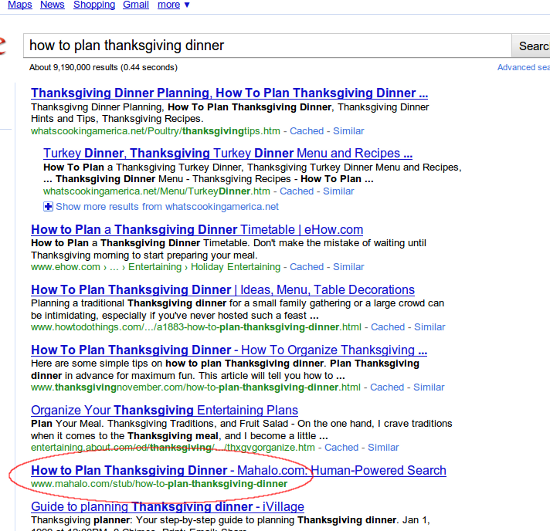
[allheart coupons] (#11)
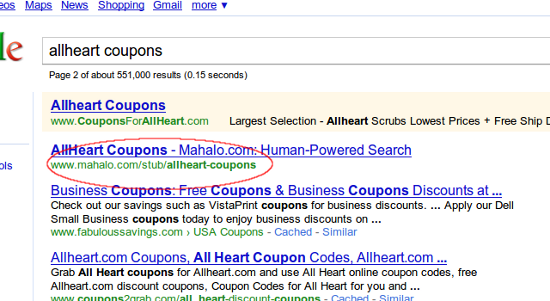
[adult friend finder coupons] (#1)
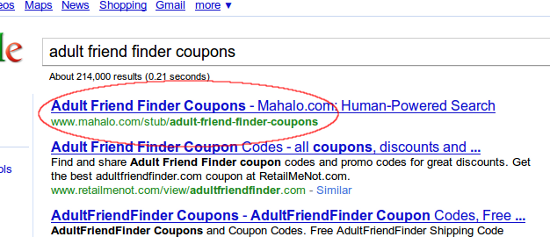
This is a page with 0 (as in none, nil, nadda, zilch) spiderable content, yet Google has deemed it worthy of ranking it #1, above every other page in the index that matches that phrase. Every.Single.One. We’re given the company line telling webmasters that in order to succeed in ranking in Google one must focus on “quality” and “unique” content, yet Google decides to give Mahalo a golden ticket for pages they can’t even see?
Wtf?
Hm. Maybe the key is that if you want your duplicate, low quality, spammy content ranked then all you have to do is block it with robots.txt…?
Obviously that is not the case, and anyone who understands at all about how these things work will recognize that statement as ludicrous… but just to be sure, let’s look at some of the non-blocked content Mahalo pages are currently ranking for:
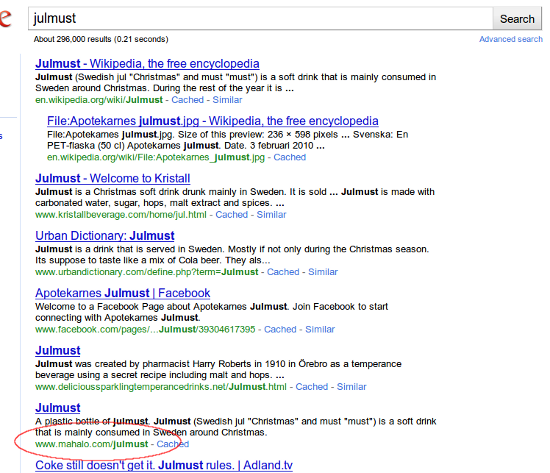
[julmust] (#7)
[The Alice B. Toklas Cookbook] (#11)
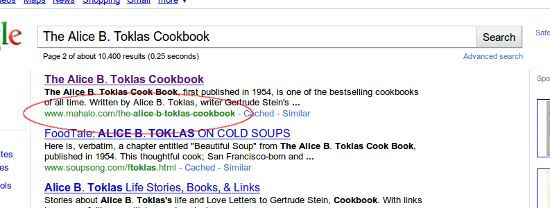
These Mahalo pages being returned are both examples of the many pages on Mahalo.com that are nothing more than content scraped directly from Wikipedia:
http://en.wikipedia.org/wiki/Julmust
http://en.wikipedia.org/wiki/The_Alice_B._Toklas_Cookbook
Note also that Wikipedia identifies some of their content as being “stubs” (the Alice B Toklas Cookbook page has a mere 261 words of content, including numbers and “a”, “and”, and “the”), but Mahalo is fine with presenting that exact same content as non-stub for whatever reason.
So, Danny, sorry… it looks as if Google did not achieve what it reportedly wanted to do with this latest update. It looks like both the low quality and completely duplicate (or even non-existant) content on Mahalo.com continues to rank. Maybe next time.
Perhaps this will shine some light on this situation:
CLICK HERE
😉
Darren, I seriously doubt that the page ranks #1 because it used to have weak content on it that is now blocked. In fact, if that is the reason that makes it even worse… the former content that Google could see was exactly what the Mayday update was supposed to be dealing with.
That’s not exactly what I was getting at. Let me explain in more detail.
The link in my previous comment reveals 2 things:
1. Mahalo is the only result for that exact sentence. To us, it’s shitty content, but to Google, it’s unique content.
2. The URL, http://www.mahalo.com/adult-friend-finder-coupons, is still indexed and has a snippet, so we know it’s been crawled and Google still has that data somewhere. This URL 301’s to http://www.mahalo.com/stub/adult-friend-finder-coupons, and as a result, it’s entirely feasible for Google to aggregate the keyword relevance data for both URLs into a single “{docID}.”
It would be a lot easier to check this theory if http://www.mahalo.com/adult-friend-finder-coupons were cached. Without that, I’m not sure how to prove this theory.
Oh, and one more thing…
Both URLs return a PR of 2.
That is because both urls are being considered the same as far as PageRank goes, that’s one of the effects of a 301 redirect. And Darren, I understood what you were saying the first time just fine. Minus stop- and less-than-three-character words, there are 80 words in that article. There are tweets with more (and frankly, higher quality) content then that page. To suggest that maybe Google is ranking that page due to it’s former “unique” content that has been pushed to the supplementals and effectively de-indexed is somewhat silly.
I found this off a tweet from Aaron Wall, and in following the thread I’m wondering (not to be obstreperous) if Michael VanDeMar has another theory?
I’m incredibly new to this whole game, so I’m seriously curious what you’re thinking by way of a theory to the madness if SEO MoFo (great name!) was wrong.
Its a slap in the face for people who take the effort to write good original content. Should we turn the other cheek now?
OMG you nailed it. I saw a couple of my clients who had content heavy website lost quite a bit of traffic and ranking. At first I thought it was maybe because of Aggressive link building but more and more I am seeing is that their content may have got them in trouble.
It is really crazy how Google keeps saying “focus on having good content geared toward user” and then penalized sites with having rich content.
btw it was a great article I send you a link from my blog…keep up the good work 🙂
Mahalo generates the pages based on an algorithm looking at Google Trends, etc. They didn’t just stop Mahalo either as numerous scraper sites who scraped my content still rank when you look up the title of articles on my website. I think Google is wrong attacking many long-term phrases but instead should put an even greater emphasis on unique content.
It seems that comparison shopping engines came out unscathed. I know we are continuing to get more traffic than ever before after the may day update
Really interesting article, I have seen many sites with low or duplicate content also rank higher during these changes for long tail results.
I came across this article today. This is great. We lost a lot of traffic in May and our ranking getting worse. We have a content heavy website and now we are getting beat by our competition that has less than 10 pages with almost no significant content. I am not sure what is google thinking!
How about all of the Yellowpages.com, Citysearch.com, etc clones? Do we really need all of SERP page 1 for a local business query to throw up 10+ nearly duplicate pages, which have nothing more than the same street address & phone number (if that much)? I see that hasn’t changed whatsoever with the recent G update. Most of these pages are scraping content as well…many sources feed directly from YP and Citysearch, in a similar way that Mahalo leeches from Wikipedia.
I saw the CEO of Demand Media say that they are getting more longtail traffic since the update.
Eli says: “We have a content heavy website and now we are getting beat by our competition that has less than 10 pages with almost no significant content. I am not sure what is google thinking!”
Eli, who owns the site competing with you? Demand Media doing better, Mahalo unchanged… I think the key to understanding this update is to follow the money. Who has financial ties to Google, either by paying them millions a month –I couldn’t help but notice a certain site in the jewelry niche that spends over a million a month on adwords is suddenly ranking again for practically every competitive jewelry and diamond keyterm–or partnering with them in some other way. Thinking that sites part of the premium adsense plan (which allows you to put more adsense units on the page than the average person) might be getting a boost.
We already know if you have the RIGHT venture capital you can get away with murder. Everything gets tied together. If Demand Media buys a content site that Sequoia (basically Google*) invested in, then Sequoia and Google suddenly have even more a vested interest in propping this site up.
*Google is Sequoia’s biggest money maker year after year, and the amount of money that Sequoia makes from Google is extremely disproportionate to its other investments.
If you’ve got the money, honey. I’m not one to usually be too into these theories, but when I see sites ranking that shouldn’t be, I can’t help but look at the public money trial.
Google does get it wrong a lot. They most likely will tweak it a bit to fix it. If not, they will pull it quietly all together.
Most of the SERPs linked in this article seem to be changing for the better.
Well, not better for mahalo.
@TwentySomething – I don’t see that. I checked the article’s links to the SERPS and saw Mahalo was actually climbing.
Fascinating expose Michael! Two possible threads for further investigation:
1) Trust of sites involved. Mahalo, with Jason’s PR, obviously gets high [algorithmic] trust. [I get that it’s humanly not trustworthy.]
2) What the difference was on balance. Perhaps there’s less total Mahalo crap ranking? Eg from 200K URLs to 100K?..
LOL, OMG thank you for this! It was a serious spirit-raiser to see so much evidence that Mahalo has still got an inexplicable edge on Google. Keep it up!!
Finally, some hard core analysis of Mayday. I like it…and the results do seem to suggest that Mayday did not achieve its objective…at least in this instance.
Really interesting, I always wondered why some stuff I have been monitoring didn’t take a dive after the Mayday Update, but this explains much…let’s see how fast Google will solve this.
@ follow the money
spot on! that’s really all you have to do anymore is follow the money.
evidence is overwhelming at this point in time, and not just about those 2 sites, but many many other interesting connections out there.
lets be honest – this is a company who for so long, has had a “get rich quick” category for their “advertisers”
that is evidence enough that they care only about money, and do not care about their users or search results.
i wander how much was spent in adwords by such famous ponzi scams like 12dailypro and studiotraffic?