Last month Jason Calacanis wrote a rather sarcastic post aimed at Aaron Wall, which I am assuming was written in response to Aaron’s post, “Black Hat SEO Case Study: How Mahalo Makes Black Look White!“. In it Aaron discusses how sites that are composed largely of nothing more than auto-generated pages wrapped in adsense can get accepted and even gain authority in Google if they have enough financing and press. In Jason’s rebuttal to this was a claim about rankings that Mahalo had “earned” (and I use the term loosely) for “VIDEO GAME walkthrough”. I originally misinterpreted what he was trying to say, and thought that he meant rankings for that exact phrase. I commented how that wasn’t exactly a great accomplishment before realizing that what he actually meant was rankings for [{insert video game name} walkthrough], and that Mahalo has a couple top 10 rankings for that genre of search phrases.
Jason sent me an email to correct me on what he was talking about. We replied to each other back and forth a couple times, and a few very interesting things were revealed in that conversation:
On Mon, 2010-01-25 at 14:46 -0800, Jason Calacanis wrote:
sorry, didn’t mean ranking for “video game walkthroughs” literally….
more like VIDEO GAME NAME walkthrough:
http://www.google.com/search?&q=call+of+duty+walkthrough
On Mon, Jan 25, 2010 at 3:38 PM, Michael VanDeMar wrote:
Yeah, realized that and pointed out that I might have misinterpreted in the next comment. I only saw one or two that you were in the top 5 though, not a slew of them. But yeah, better than the generic version.Thing is that you still have tons of auto or near-auto generated content out there ranked, stuff that is nothing more than noise, including stuff you are boasting about ranking for:
http://www.mahalo.com/need-for-speed-prostreet-walkthrough
I commented about this last year I believe… this is not a legitimate or ethical way to go about what you are doing:
1) Auto-generate tons of pages with no content, with AdSense embedded on them, based solely on search phrases
2) See what winds up ranking
3) Go in and put valid content in afterwards, pretend that all along the content was not only valid, but actually better that what you outranked.You want a more palatable model? How about this… there are tons of sites out there that are full of great content that no one will ever see, because they’re simply not seo’d (ie. unknown and unlinked). Why don’t you:
1) Find a way to identify the search results that are already full of crap sites
2) Identify quality sites that should be there instead, and
3) Use your pull and popularity to get *those* sites ranked.If you find a way to do just that and somehow build a successful business model around it then that would be much, much better than what Mahalo is now.
-Michael
On Mon, 2010-01-25 at 15:43 -0800, Jason Calacanis wrote:
the part you’re leaving out is:a) we used to noindex these and we are going to again
b) if any page gets any traffic we pay someone to build it out–so it’s only short for a couple of days. 🙂if a page is started by a user and is short it a) won’t rank 99% of the time and b) if it happens to we see it in analytics and build it out.
not really a big deal IMO
best j
Let’s take a look a little closer to some of the things that Jason is saying here:
“we used to noindex these and we are going to again”
At one point Mahalo had the noindex tag on the pages that were fully automated, and Jason is freely admitting that they should have the nodindex tag now. These pages have no added value and should not be indexed by Google. Jason must believe this, or he would not say that they were planning to add the noindex them again. If he thought they deserved to be in the index then there is no reason to tell the search engine spiders not to include them. Now, according to Jason’s rebuttal to Aaron, the removal of the nodindex tag was an “accident” that happened in the migration to Mahalo 3.0. For those who do not know, Mahalo 3.0 was released back in November of last year. Mahalo is a template driven site. All it takes to “fix” the tag that was lost “by accident” is a coder opening up the template header and including 1 line of conditional code. In the 3 months prior to our conversation, and in the 3 weeks since, no one has bothered to do so. To this day those pages are still getting added to the index at a very large rate.
How large, you might ask? I have been checking here and there for the past few weeks, and when I looked on any given day Google was reporting from 2,000 to 20,000 new pages on Mahalo.com:
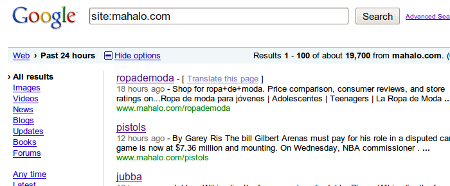
I clicked through quite a few of these pages to see what the content looked like. Almost every singe page I looked at was completely automated content. In fact, when I looked today, the only one I found that wasn’t totally automated was the Mahalo entry on Hootsuite… which happened to have 2 additional manually added sentences in it, content which “enhanced” the scraped content that surrounded it: “HootSuite is the professional Twitter client. With HootSuite, you can manage multiple Twitter profiles, pre-schedule tweets, and measure your success.” The entire “Human Powered” portion of that page is tinier than just one AdSense block located directly under it:
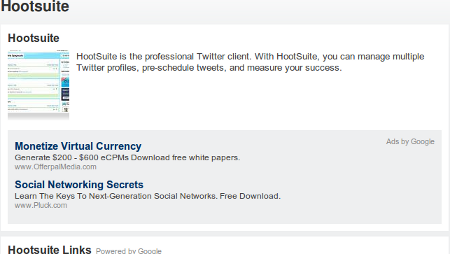
And that AdSense block is one of 4 located on the page. Yeah, let’s hear it for “added value” folks.
As a side note, it looks like Jason is violating Google AdSense TOS by placing more than 3 AdSense blocks on each page. Not entirely sure why they are letting him do that, since supposedly that lowers the overall value each advertiser gets… but I digress.
“if any page gets any traffic we pay someone to build it out”
Here Jason is clearly admitting that he thinks it’s fine to rank your scraped content first, and then add quality if and only if it gets traffic (and remember, 1-2 sentences of “quality” is fine). Essentially he’s saying, go ahead and spam, but if it looks like it might get enough traffic someone will actually notice, add content.
I wrote back:
On Mon, Jan 25, 2010 at 4:51 PM, Michael VanDeMar wrote:
So, you’re not denying that is indeed your model here (rank first, quality later), you’re just saying that you think that’s it’s fine to do it that way, since you pay people to build it out within a couple of days after you start to get traffic?Your assertion that a page on your devoid of content won’t rank is completely untrue, by the way. Generally people with quality content wind up ranking because other people link to them. That’s what the whole basis of Google’s base algorithm is built upon. Your site, however, gets pages ranked solely by virtue of other internal pages linking to them. You have so much link juice, due mostly to controversy and press, ranking power that you spread around your site from one page to another, that you can rank relatively competitive phrases with no effort at all. That does not somehow make the page quality due to some sort of mystical link juice feedback. Quality attracts link juice. Link juice does not impart quality.
Take a look at these pages, all which rank with pretty much nothing but links from within Mahalo itself:
http://www.google.com/search?q=valentine%27s+day+cupcakes
#1: http://www.mahalo.com/valentines-day-cupcakes
1 external link, from a scraper: http://search.yahoo.com/search?p=link%3Ahttp%3A%2F%2Fwww.mahalo.com%2Fvalentines-day-cupcakes+-site%3Amahalo.comhttp://www.google.com/search?hl=en&safe=off&num=10&q=halo+3+walkthrough&btnG=Search
#5: http://www.mahalo.com/halo-3-walkthrough
Again, only linked externally from another scraper: http://search.yahoo.com/search?p=link%3Ahttp%3A%2F%2Fwww.mahalo.com%2Fhalo-3-walkthrough+-site%3Amahalo.comhttp://www.google.com/search?q=how+to+invest+online
#8: http://www.mahalo.com/how-to-invest-online
Zero links from external sites, even from scrapers: http://search.yahoo.com/search?p=link%3Ahttp%3A%2F%2Fwww.mahalo.com%2Fhow-to-invest-online+-site%3Amahalo.comGoogle describes it’s ranking algorithm as something that leverages the democratic nature of the web. No one, however, is voting for your pages. Why should they rank? Simply because you paid someone to flesh them out?
-Michael
PS. Do you mind if I blog this? Or are any of your answers being said with an expectation of privacy?
On Mon, 2010-01-25 at 17:00 -0800, Jason Calacanis wrote:
Actually, most of our pages come in VERY LARGE now because we don’t allow folks to just make them on the live site any more. They have to go through Mahalo Tasks now. in the old days it was a free for all like Wikipedia/Squidoo…. we didn’t like the results.Very few of our pages start short. So, it’s not really a strategy to put up short pages and wait… our strategy is to get a TON of people to make pages in Mahalo Tasks.
Think about it: which is a better way to build a business… make a bunch of stubs or make a bunch of high-quality pages? The later is better and it’s really not very expensive. Especially now that we have revenue sharing with our page managers.
The three pages you’re talking about all have a LARGE amount of original content, and I would say they are B+ to A+ content, no? I think google and yahoo take into account a large amount of content plus the amount of time a user sits on a page. At least i’ve been told that they look at time spent on page. as you can imagine… the time spent on a recipe, walkthrough or howto article is VERY LONG. 🙂
thanks for the feedback!
best j
Again, let’s look at what he’s saying here:
“we don’t allow folks to just make [pages] on the live site any more. They have to go through Mahalo Tasks now.”
That’s right, Jason would like us to believe that the Mahalo pages, like the one on 13 year olds and rape, all now pass an editorial review before going live. Even if that were true (which it isn’t, btw) I don’t think that I would be boasting that, based on the pages that I looked at.
in the old days it was a free for all like Wikipedia/Squidoo…. we didn’t like the results.
Now Jason Calacanis is saying that the 100% user contributed, zero ads Wikipedia is nothing more than a “free for all”, and that his 99% auto-generated content content laden with AdSense is therefore better. Gotcha.
“Very few of our pages start short.”
Either Jason thinks he’s talking about a different site, or he has absolutely no concept of what the phrase “very few” actually means. Currently when I look, Google tells me that Mahalo has 356,000 pages indexed:
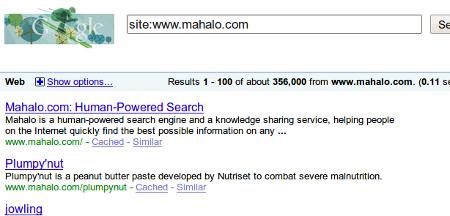
As I mentioned earlier, in contrast to “very few” of these pages being “short”, the vast majority of them are nothing more than scraped content. From what I can tell it looks like less than 4% of the Mahalo.com pages getting indexed on a daily basis actually involve humans adding unique content in to them. The rest of the pages are being auto-generated by a Mahalo bot aptly named “searchclick”. If you go to any of these non-content pages and click on the “View Page History” link in the bottom of the right column you can see exactly who it is that generates the majority of this “Human Powered Search” website:
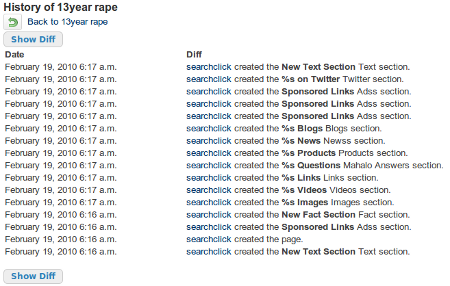
“searchclick” is of course not an actual user. It’s the name of the robot that Mahalo uses to generate all of these pages on it’s site. According to the Mahalo website,
Searchclick is not really a user at all. The name “searchclick” is used to represent a individual “search click” by a Mahalo user who has searched a particular term and Mahalo made a “created by searchclick” meaning the page had been searched for the first time.
These pages on Mahalo that are getting indexed by the thousands are nothing more than searches that users performed that no one thought valuable enough to create a topic page for in the first place. The content used to populate these pages is nothing more than scraped versions of other websites search pages, such as Youtube, Flickr, and Google itself.
Google is very clear on it’s viewpoint of indexing search pages. Matt Cutts, head of Google’s Webspam team, wrote about the subject back in 2007:
But just to close the loop on the original question on that thread and clarify that Google reserves the right to reduce the impact of search results and proxied copies of web sites on users, Vanessa also had someone add a line to the quality guidelines page. The new webmaster guideline that you’ll see on that page says “Use robots.txt to prevent crawling of search results pages or other auto-generated pages that don’t add much value for users coming from search engines.” – Matt Cutts
There really is not a whole lot of room for ambiguity in what Matt is saying.
As it turns out, Mahalo can not block these pages using robots.txt. They go out of their way to make these search generated pages blend in with every other page on their site. Not only are they all located in the same root directory, there is nothing at all that allows the fact that they are auto-generated to be detected in any sort of machine readable way. Is this by accident? From the way Jason talks, you would think so. However…
The mere creation of pages is not enough to get them discovered and indexed in the search engines. The search engine spiders must have some means of locating these pages in order to know that they exist. Most sites simply rely on links from other pages on their sites, or links from other people’s sites, for their content to get noticed. There are alternate means though. For instance, Google allows webmasters to set up special sitemaps, meant for search engine spiders alone, in order to insure that sets of pages that the webmaster considers important do in fact get found. These spider-only sitemaps are in XML format, and are not meant for human visitors to use. Does Mahalo use XML sitemaps?
Yep, they sure do. In fact, they use a dynamically generated sitemap, one that is generated on the fly with a url parameter, “p=”, used to distinguish which page of the sitemap you want to view. If we actually open up Mahalo’s sitemap, what do we see?
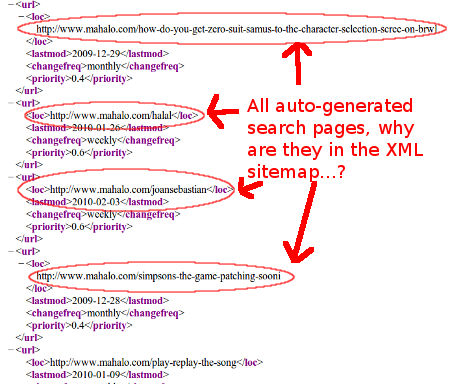
That’s right… Mahalo’s XML sitemap is packed with tons of spammy auto-generated pages for Google find. Not only is Mahalo not blocking these pages from getting indexed, they are actually going out of their way to make sure Googlebot finds them.
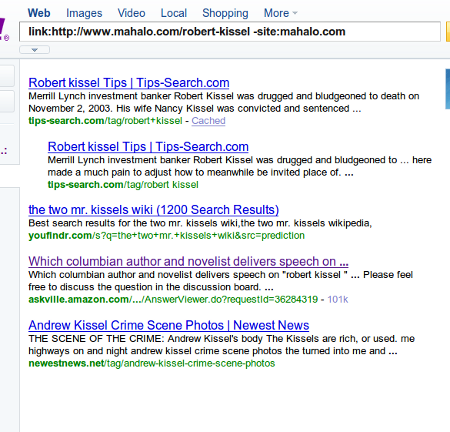
While Jason’s assertion that these pages don’t directly generate a ton of traffic for him may in fact be true, they do play a very important role in his overall ranking scheme. With nothing but the power of the domain they reside on many of these very little competition, zero traffic phrases will actually result in rankings. On occasion you will find spammers scraping these rankings from Google, which then result in a very low pagerank link back to Mahalo.com. Individually each of these links adds almost no value. However, as I mentioned earlier, Mahalo has hundreds of thousands of these pages indexed. In conjunction with link juice from 1 or 2 links from his own blog often times Jason can now get some moderately competitive phrases ranked with no effort, or votes from the rest of the world, at all. For instance, currently at the top of many pages on Mahalo you will see a link to the page for Robert Kissel, who happens to be in the news currently. Search on Google for him and you can see that Mahalo page is currently in the top 10. If we look at the links pointed to this page we see that aside from interior pages on Mahalo.com, exactly 4 sites link to it, 3 of which are from scraping Google’s results:
Even if we are to believe that the Jason himself believes the naive assertion that the sheer amount of content or time a visitor spends on a page are major ranking factors, we all know that those alone will not get you ranked, even if your content truly is quality. As to Jason’s statement that the pages on Mahalo are “quality” and deserve to rank? In most of the cases that I saw, and I am talking about the “human powered” ones now, they simply aren’t. Take for instance Mahalo’s top 10 ranking for [need for speed prostreet walkthrough], if you look at the page there isn’t even a walkthrough on it:
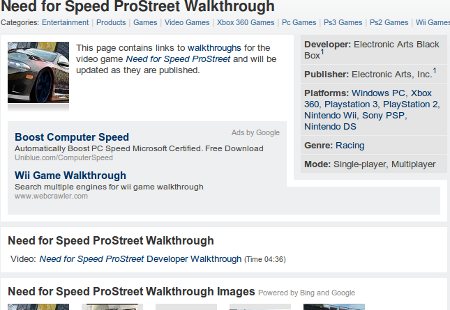
Aside from that tiny little blurb and links scraped from the search engines, the only thing on that page is an embeded video of a walkthrough that was made by someone other than a Mahalo user… and that video doesn’t even exist anymore. If Mahalo used content that they generated and hosted themselves that would never be an issue.
At this point in the game of course, simply noindexing the pages in and of itself is not really a solution. Unless Mahalo moves the search auto-generated content into it’s own subdirectory so it can be blocked by robots.txt, noindexes and nofollows the existing pages (to prevent grabbing unwarranted juice from serps scrapers), and removes them from their sitemap, then they are in clear violation of Google’s Webmaster Guidelines. Why Google won’t actually take action on them is anyone’s guess.
Use a site search other than Google.com for more realistic numbers
http://www.google.co.uk/search?q=site%3Amahalo.com%2F&pws=0&gl=UK
To be honest noindex is probably enough, why penalize the people who were scraped with no link love.
I am devided as to the value of parts of Mahalo though have always criticized the autogen pages which at one time had no content at all and were an alternative to 404s but returning a 200 ok
Andy, not sure what you meant by “more realistic” on the numbers, I get “Results 1 – 10 of about 2,300,000 from mahalo.com” when I use Google.co.uk, which seems way overinflated if you ask me. What do you show?
As to the nofollow, I meant to block the link juice flowing back into his site. See, you may not realize this, but Jason already nofollows the links he scrapes from the serps. He doesn’t want any of that micro link juice he is harvesting from other scrapers to go outside his site.
I wasn’t referring to you nofollowing Jason – I would certainly do the same to those pages.
I didn’t realise he was nofollowing the links, but I would do the same as he can’t trust the source… but as I said to him on Buzz last night what he needs to do is get permission to scrape RSS feeds (& show excepts), then there is also a layer of human review.
But then I might still nofollow because it is still UGC & you know Google…
My belief is that everything but .com is a more accurate representation though also only a fraction ever see traffic, after all do you really think Google is changing out that many of the scraped pages so quickly?
Right, but you had said this:
I was merely pointing out that they already receive no link love, and the juice gathered from these pages only flows back into Mahalo itself, and therefore should be nofollowed as well as nodindexed.
Although, to be honest, what should really happen is that they get the same penalty/ban any other spammer using these tactics would get, and have to go through the same cleanup process and reconsideration request that everyone else does. I just doubt that’s going to happen.
Props for solid research and maintaining a conversation with the subject of your topic. Taking the extra step to actually talk this through with Jason makes it much more authentic and valid.
Mahalo by the way means “gratitude” or “respect” – Wonder if this method of page creation meets the definition..?
Thanks for the feedback.
We’re removing any page with less than 200 original words and we’re not going to let folks create short pages (we call them stubs) any more.
We’re not trying to spam anyone, and to be honest these pages are < 1% of our revenue and a very small % of our traffic (no idea to know how small, but very small… like single digets).
We're only interested in creating quality pages and if the SEO community or Google feels that these short pages are no appropriate to have we'll get rid of them. of course, Topix and Kosmix have tons of topic pages as well, so I'm not sure what the difference is beyond the fact that I called SEO "bullshit" at a conference six years ago.
Thanks to everyone for the words of support and to the haters… well… there is nothing I can say to change your mind so I guess… well… hate on!
best jason
Wow, you must have a lot of time on your hands – looks like compiling this posting took some serious work… but unfortunately, there are 100s of web catalogues out there applying the same principles; in the long run, Mahalo will use human users and since social search will change the game anyways, I wouldn’t worry too much about these follow/nofollow tactics.
Jason, since you so conveniently decided to ignore my rebuttal to your troll defense on Ycombinator, I’ll go ahead and re-post it for you here again:
—-
Jason, did you even read my article? This isn’t about the traffic those autogenerated pages get, it’s about the fact that through the minuscule amounts of PageRank that they are each capable of grabbing, you are now able to rank your mediocre pages with absolutely zero influence from the rest of the web.
We’re not talking about stub pages, it’s all the fully automated bullshit that you are generating. They not only need to be deindexed, they need to be nofollowed or removed altogether.
How is it you are out there playing the wounded puppy when apparently you haven’t even read the articles or followed the reference links? You can’t just skim this one and then craft a rebuttal and think you’ve addressed the issue. There’s a lot of data in those paragraphs you apparently just skimmed over (if that even).
You have over 500,000 pages listed in your xml sitemap, and Google appears to have over 330,000 of them indexed. Click on this link, please, and actually go look at 10-12 of the pages we are talking about here:
http://tinyurl.com/yzmxq7b
Tell me how long it takes you, just by clicking through, to find even 3 pages that have any human interaction in them whatsoever.
Maybe, just maybe, you really don’t have a clue what is happening. I personally don’t believe that’s the case, but if so then whoever it is you have working for you that set this up knows how to spam like a pro.
—-
Now, I am not sure what school it is that teaches you to avoid answering any factual critiques of your actions by ignoring anything containing those facts you can’t refute and instead simply calling those who discuss them “haters”, but contrary to what you might think, it doesn’t make you look innocent. What it does is make you look quite a bit like a dishonest prick, truth be told.