 Ok, so, looks like Rand and gang finally decided to reveal their top-secret recipe about how they gathered all that information on everybody’s websites without anyone noticing what they were doing. There was quite a bit of hoopla over the fact that when they announced their new index of 30 billion web pages (and the new tool powered by that index), due to the fact that they never gave webmasters the chance to block them from gathering this data. In fact, they never even announced their presence at all.
Ok, so, looks like Rand and gang finally decided to reveal their top-secret recipe about how they gathered all that information on everybody’s websites without anyone noticing what they were doing. There was quite a bit of hoopla over the fact that when they announced their new index of 30 billion web pages (and the new tool powered by that index), due to the fact that they never gave webmasters the chance to block them from gathering this data. In fact, they never even announced their presence at all.
While this is a huge breach of netiquette as it pertains to crawlers, at least today Rand finally announced that they are now disclosing their sources for data. In fact, this was how he worded it to the community:
we are now disclosing our sources for data – Rand Fiskin, SEOmoz CEO and really, really open guy
Better late than never, right?
The thing is, as I was looking over the list of bots that you would need to block in order to prevent mozzers from gathering your data, I noticed this subtle, easy to miss pattern in what they were listing. You have to look really, really close to see it, and the untrained eye might never see it at all, but luckily, eventually, I did see it for myself:
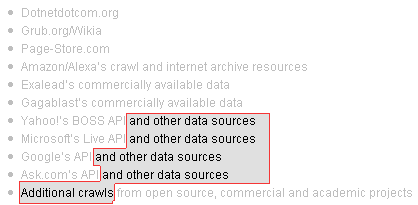
That’s right folks, if you do decide to keep moz out by blocking all of the big guys (Google, Yahoo, MSN, Ask, Amazon, and Alexa), the lesser known guys (Dotnetdotcom, Grub, Page-Store, and Exalead), and that one fictional guy they threw in there (Gagablast), you still won’t have them blocked. Fear not though… after much work, I finally figured out that Rand was indeed true to his word, and that they did in fact release enough information to block the bots. All you have to do is add the following lines to your robots.txt, and you’ll be golden*:
User-Agent: *and other data sources
Disallow: /
User-Agent: Additional crawls*
Disallow: /
See? I got ya covered! 😀
Seriously though, despite the fact that Rand and Co. are still less than forthcoming about all of the bots that are used (I’m guessing he doesn’t actually know, to be honest), something much more revealing is highlighted in this information, namely, they lied about having their own crawler.
Let’s take a quick review of some statements Rand made in the initial announcement about the tool:
- Our crawl biases towards having pages and data…
- As others who’ve invested energy into crawling the web…
- our crawl biases towards this “center”…
- Our process for crawling the web…
- Moving forward, we’ll… invest in better and faster crawling…
- In comparing our crawls against the engines…
- we’ll be releasing more information about our crawl…
You also have statements made by moz employee Nick Gerner like this:
- we’re crawling everything we can…
You even have him claiming bullshit like this:
We do prioritize the crawl according to pages we think are important. For now, and probably for the foreseeable future we’re going to rely on link endorsement to make that decision. Make good content, get good links. Keep it publicly available. We’ll get there soon enough – Nick Gerner, moz employee
That’s right, not only did they claim that they were crawling the web, they wanted us to believe that they prioritized how they crawled based on an importance algorithm! 😀
I have to admit, Rand, it’s pretty bold to basically admit this late in the game that you guys lied through your teeth and grossly misrepresented the facts, just so you could appear to have accomplished a much bigger task than you actually did, all in the name of getting more money from webmasters. That’s a much bigger admission than saying you cloaked your bot, if you ask me. Gratz on coming clean.
Many years ago, I had an exchange with Rand about building a tool that would make the toolbar PR obsolete.
Unfortunately, I feel that while that was likely a prime motivation for “Linkscape,” it’s missed the mark while also infuriating a significant portion of the SEO/webmaster community.
I just hope that exchanges like this (and discussions like the ones that are occuring in Sphinn and twitter) will eventually lead to such a tool.
And Rand…I know that you’re in a tough spot…trying to protect the value of your product by withholding certain information…I just think that in order for this product to ever truly reach it’s potential, you’ll have to be 100% forthcoming with the mechanism that powers it.
But then again, what do I know?
This is really becoming a circular argument. The impasse seems to be there are some folks who want more information, and SEOmoz for their own reasons (however you choose to subjectively interpret them) are not going to tell you. They have a (I’m sure) significant investment in labor, research and marketing involved and are not going to throw out the baby with the bathwater.
Thanks for clearing that point up. Since SEOmoz does not itself grab page content from my website, I gather that the creation of Linkscape did not add to my bandwidth costs.
One of my worries was that aside from G/Y/M, now there is yet another entity fetching every single one of my webpages (with no benefit to me). Glad to hear that is not the case.
Even if bandwidth is not an issue, there’s still the matter of competitive intelligence. It would be nice for webmasters to be able to submit a request to have their entire domain removed from Linkscape, without adding a meta tag to every single page. Pretty please? 🙂
@Rand
From what it sounds like you have enlisted the help of bots built by a third party(s), but work according to your requested specifications, and will continue to work in while you keep the company(s) that you are working with on retainer.
Let’s peel back the layers.
Does Linkscape utilize a first party solution for getting documents into its index? In other words, is there in-house technology at SEOMoz that actually makes contact with servers across the web to put into the Linkscape index?
I think the answer has become a pretty clear “no”. From the statements I’ve read, and the UAs released, I can only assume that the bots that are directly in contact with the pages being downloaded are built by outside sources.
Next, where do the bots commissioned for the Linkscape tool download their content to? Are the spiders visiting pages and downloading them directly to servers under the control of SEOMoz?
This is something I’m not clear about. My guess is that the companies that have built the bots get the data directly to their own servers and SEOMoz gathers it from there.
Last, are the spiders actually behaving according to SEOMoz’s specifications?
More specifically, are the spiders working in a such a way that you have designed them to, or are you simply being selective about the information you choose to receive while they act as they usually do? What level of control do you have on the actual behavior of the bots as they crawl the web?
And, I want to be clear, I’m not supposing that any of my assumptions are really how the tool works. I have come to those conclusions based on what I’ve read and what I feel I have been lead to believe, any clarification would be extremely welcomed.
Marty – yeah, we do have some things, mentioned above, that we’re not disclosing.
Tummblr – that’s not exactly right. The crawls that feed into SEOmoz do use bandwidth, but we don’t download plug-ins or images or scripts so it’s just the raw HTML, which significantly reduces the amount of bandwidth compared to something like Google/Yahoo/Ask/Archive/etc.
Of course, when we backfill with these folks’ data, we’re not incurring any additional bandwidth.
On the domain side – we’ll certainly look into a way to block an entire domain, but we’ll probably need to build a verification system for webmasters and site owners first.
“That index was built by crawlers we control and may, now or in the future, pull data from any of the sources listed.” Rand all the noise here is about having a respected robots block command to the indexing crawlers (Dan Thies’ original idea he sent you over the email). Rand, I have never seen you circle around the topic before. You have to admit; some of your closest friends in this field opposed you on this issue. I think I will refuse when someone offers me VC money next time. Corporate SEO sucks. I realize this is a make or break deal for your VC agreement. Just to get to Aaron Wall’s blog post on this topic, how much longer can you survive the negative branding. Anyhow, I am out to block my websites to non search engines. It is a shame this issue came to this level. Whether or not your opponents in this issue are right or wrong even Ali did not pull this much Rope-a-dope in a boxing match as you did in Sphinn and here. I wish you and your partners the best in your ventures but it seems this will hurt you as much as it will help you. Good luck.
Thanks Mert – I think that anytime we can’t have full disclosure, and this is certainly an issue where that does exist, we’re going to have misconceptions and confusion. For that, I certainly apologize. I hate to run around in circles and I feel that I’ve tried to be as direct as I can without compromising the information we need to protect.
Rand, if you build a crawler that has indexed 30 billion pages what is the robots.txt UA or IP addresses to block “that” bot?
For now i don’t care about your long list of random other well known bots you may or may not backfill data from.
I want to know the UA or IP of YOUR bot scraping 30 billion webpages that you claimed to have engineered from the gound up.
I control 23 servers hosting many thousands of sites and i want to firewall your bot from the lot.
Thank you and bookmarked to receive a reply.
NotHappy – the list of sources on the page is as far as we’re going with disclosure (primarily for competitive reasons). However, that list does include all the sources we use, and they all obey robots.txt. You can also keep your results out using the meta seomoz noindex tag.
Goodness; Please read my last post prior. I stand by that.
Ridiculous.
Let’s see now; I’ve read all the new threads at sphinn. I’ve read the blog posts in here. I’ve read pretty much everything Rand has had to say on the matter.
OK; Each one of my clients pays Rand $79 per month for the privilege of seeing his views on link values, etc.
OR:
Each one of my clients can stick up a Rand meta tag that just might keep all pages out of his Linkscrape tool. Each one of my clients also gets the benefit of having another SEO’s meta tag on each page of their site. OK fine.
SO:
Shouldn’t Rand pay each one of my clients an advert fee? I’d say about $79 per month should be OK.
BTW: I have zero intention of using this meta tag… which is bogus anyway… to block pages from Linkscrape. SEOMOZ better give us a GOOD way to block his stuff via robots.txt. If you don’t do this; you can bet NO ONE worth two shites is going to consider SEOMOZ a best practices of anything in the future. As it is right now; I highly doubt you ever win over the people in this industry no matter what you do at this point, because of the shabby/shitty/sleazy/slimy way you launched your new product. I could give a rats ass any value the tool has at all as that is not the issue or the point of why I am pissed off.
Here’s the thing though, if you use a meta tag or an entry in robots.txt, and you’re worried about your competitors finding you or your link network, you’re still going to be hosed because a google search for-
“robots.txt” “dotbot” filetype:txt
will quickly reveal who’s using a particular UA exclusion. Same for meta tags. The Internet is too open to hope to hide anything unless you disallow everything or even better, stick it behind a firewall of some kind.
Great post. I think, what happened here is they drew the line too thin on ‘hype’ for their new product. I for one thought they hype was over rated….. and clearly so did many…
Marty, the vast majority of the search you mentioned will show people talking about robots.txt, not individual robots.txt files. As a general rule those only get indexed if someone links directly to them… just like any other file on the internet.
As for people’s reasons for not wanting their information in the index, it’s simply their right.
Just as i thought Rand, the old “Can’t say competitive intelligence” line which puts SEOMoz at the bottom of the barrel with all the other scrapers. Actually they are better, they are harvesting it for things like spam which i can identify and do something about.
So looks like your Dotbot (which may be a red herring anyway) has been issued a /28 so:
# iptables -A INPUT -s 208.115.111.240/28 -j DROP
That will block 208.115.111.240 – 208.115.111.255 at the firewall (The Dotbot site is using 208.115.111.242 if you visit in the browser)
BTW Rand, how did you receive a /28 IP allocation? Running a scraper network is not valid ARIN justification. Might have to send off an email.
Anyhow if everyone issues this command:
# iptables -A INPUT -s 208.115.111.240/28 -j DROP
Alternatively you can block that IP range with .htaccess if you don’t have root access, and i will dig in to the logs and see what this LinkScraper is doing.
Sorry to say, all respect i had for SEOMoz is now gone and i will not be visiting it again.
@Nothappy; I would appreciate it if you could please write up a blog post about how “exactly” website owners and webmasters can block this bot. If not you; someone you give the info to would suffice. I think it would be very beneficial to the industry. This bot is like any o’l rogue bot not wanted on our servers. It needs to be dealt with by a good majority. What I mean is, make things very clear so as a new webmaster/owner clearly sees what to do step by step.
Well, blocking by IP is ok as long as they don’t decide to switch or add new IP’s. The thing is, that’s one bot, and I still firmly believe that it only accounts for a small amount of the collection process they are claiming. It’s the only way that things add up.
Also, since that’s like closing the barn door after SEOmoz kicked it in and raped the horses, here’s a possible method for dealing with what they took already:
https://smackdown.blogsblogsblogs.com/2008/10/21/how-to-remove-your-website-from-linkscape-without-an-seomoz-meta-tag/
Doug (Or anyone else) feel free to write a post with this info, but as Michael points out it’s not a single bullet proof solution because they can buy more IP’s and it doesn’t stop the “other sources”. But it will block the /28 IP block that has been assigned to Dotbot.
The /28 is a block of 16 IP addresses, in this case from:
208.115.111.240
to
208.115.111.255
So if you firewall those 2 IP’s and the 14 in between you will be blocking the Dotbot IP range. The Dotbot site itself is hosted in the http://208.115.111.242 IP.
In the past i have found the best way to deal with situations like this is to target the data sources rather than trying to fight the offender.
Our company is writing letters to all data sources on the LinkScrape page besides the big 3 (G, Y and MSN) notifying them we have completely blocked their crawlers from 23 webservers encompassing thousands of websites due to the data harvesting practices of SEOMoz.org who are utilizing and selling their data services.
I doubt these companies will be impressed when the value of their services are lowered, user experience reduced etc because of some company in Seattle flogging $79 a month subscriptions with the data. Especially when they realize they have been blocked from sub 5,000 Alexa sites due to SEOMoz.
Interesting enough, the project’s code name was Carhole, and the registered name for dotnetdotcom.org is Jeff Albertson. Jeff Albertson just happens to be comic book guys name…………
I have also been ordered to fight this on our European servers that currently host 32,000 websites and complaints have been filed. I think this will have seriosu repurcussions.
Thanks for the pertinent info on these goofballs. I have also found that blocking them by user agent helps too. The updated signatures for {my spammy product} will be able to deal with these keyword scrapers even better.
I did try to block them before by domain, but they weaseled around that, the give-away was their user agent showing up from other IPs. I just wanted to make sure (and this page helped me decide) that I wanted to deep-six their crawler from wherever it came from.
I personally would rather toss them a 403 a few times with reasons, than give them a robots.txt . Most scrapers, and bot probes (laycat.com) just ignore robots.txt anyway. After they hit {my spammy product} 3 times, it switches them to a 503 permanently. Quite better at bandwidth saving.
Sorry to resurrect an old thread, but has ANYONE figured out how to block linkscape outside of the ridiculous meta tag?
Well pardon me, I was just trying to help. Seems a GNU General Public License author can’t get any respect anywhere.
Please deleted this post, and the previous one I made. I surely don’t want to be associated with the likes of you!
@Ryan – you can block the linkscape UA via robots.txt
User-agent: rogerbot
Disallow: /
( Source: http://www.seomoz.org/dp/rogerbot )
personally, i love the seomoz tools so I wouldn’t be blocking it.
Actually, Yatin, that is a different tool that they launched last May. Also, based on that tool showing up in Project Honeypot, it looks like that tool isn’t obeying robots.txt either, regardless of what they say. The Linkscape tool still doesn’t identify itself as such to this day.
but Michael, as per seomoz blog rogerbot is the name of their crawler and although i haven’t checked my server logs to see visit by rogerbot, i do NOT think :
a) seomoz would have two different crawlers
b) Rand would risk brand equity by ignoring robots.txt like spam bots do 😉
Regardless of what your misconceptions about Rand’s ethical practices are, Yatin, that is a completely different bot from Linkscape, and the rogerBot you are discussing has in fact wound up in Project Honeypot’s database.